Introduction
When people talk about machine learning, they often describe it as a single thing. But machine learning comes in different flavors—each suited to different types of problems, different data, and different goals. Understanding these flavors is essential for anyone building, buying, or working with AI.
The three main approaches are supervised learning, unsupervised learning, and reinforcement learning. Each works differently. Each requires different data. And each excels at different tasks.
Supervised learning learns from labeled examples—like a student with an answer key. Unsupervised learning finds patterns in unlabeled data—like exploring a new city without a map. Reinforcement learning learns through trial and error—like training a dog with treats.
This article explains each approach in simple terms, with real-world examples, and helps you understand which one to use for different problems. Whether you are a business leader evaluating AI investments, a professional working with data teams, or someone building foundational AI literacy, this guide will help you navigate the machine learning landscape.
For a foundational understanding of how AI training data works, you may find our guide on AI Training Data: How to Prepare Datasets for Accurate Models helpful as a starting point.
Throughout, we will highlight how MHTECHIN helps organizations choose and implement the right machine learning approach for their specific problems.
Section 1: The Three Flavors of Machine Learning
1.1 A Simple Framework
Machine learning algorithms learn from experience—but the type of experience differs.
Supervised learning learns from labeled examples that include both the input and the correct output. The key question is: given an input, what is the correct output?
Unsupervised learning learns from unlabeled data—input only. The key question is: what patterns or structures exist in this data?
Reinforcement learning learns from rewards and punishments based on actions taken. The key question is: what actions lead to the most reward over time?
1.2 A Simple Analogy
Imagine teaching someone to play chess.
Supervised learning is like showing the student thousands of games with moves labeled as “good” or “bad.” The student learns to recognize patterns from expert examples.
Unsupervised learning is like giving the student a collection of game records and asking them to find patterns—which opening styles tend to appear together, which strategies cluster.
Reinforcement learning is like letting the student play games against themselves, getting points for wins and losing points for losses. Through trial and error, they discover winning strategies.
Each approach works. Each requires different preparation. Each is suited to different problems.
Section 2: Supervised Learning—Learning from Labeled Examples
2.1 What Is Supervised Learning?
Supervised learning is the most common form of machine learning. The algorithm learns from labeled examples—data that includes both the input and the correct output.
Think of it as learning with an answer key. The algorithm sees examples, makes predictions, compares them to the correct answers, and adjusts to improve. This is the approach behind spam filters, fraud detection, and price prediction.
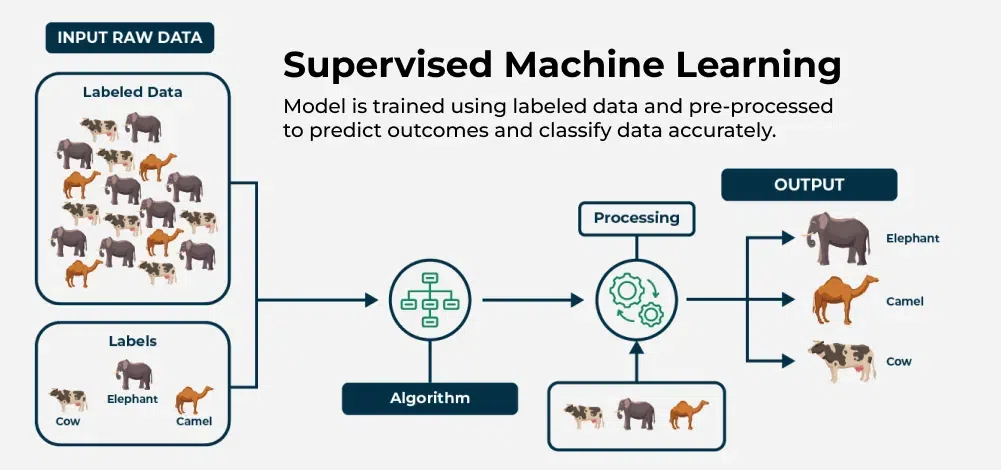
2.2 How Supervised Learning Works
The process follows a consistent pattern. First, you collect labeled data—examples where the correct output is known. Then you split the data into a training set (to teach the model) and a test set (to evaluate performance). The model trains by learning patterns that minimize error on the training set. Once trained, you evaluate it on the test set—data it has never seen—to measure how well it generalizes. Finally, you deploy the model to make predictions on new, unlabeled data.
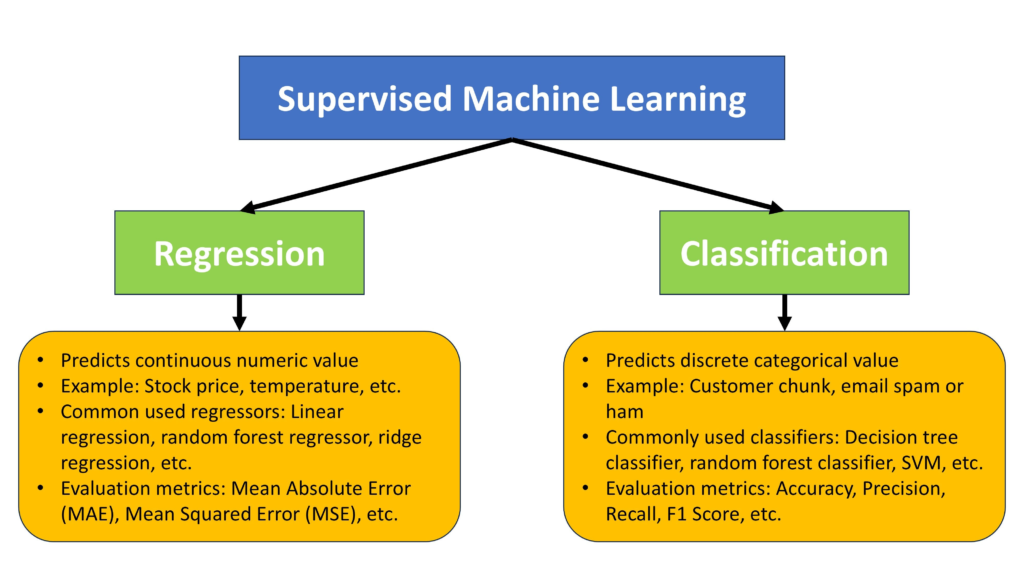
2.3 Two Main Types
Supervised learning comes in two main varieties.
Classification predicts which category an example belongs to. Is this email spam or not? Is this transaction fraudulent or legitimate? Is this image a cat or a dog? The output is a discrete category.
Regression predicts a numerical value. How much will this house sell for? What will sales be next quarter? How many passengers will fly tomorrow? The output is a continuous number.
2.4 Real-World Examples
Email spam filters are classic classification systems. They are trained on millions of emails labeled “spam” or “not spam,” learning to recognize subtle patterns—combinations of words, sender reputation, email structure—that indicate spam.
Credit scoring uses classification to predict whether a loan applicant will default. The model is trained on historical loans with known outcomes, learning which combinations of income, debt, and payment history indicate risk.
House price prediction uses regression. The model learns from past sales—size, location, age, condition—to estimate the value of new properties.
Medical diagnosis systems classify medical images as showing signs of disease or not, trained on thousands of images labeled by expert radiologists.
Customer churn prediction identifies which customers are likely to leave, enabling proactive retention efforts.
2.5 Common Algorithms
Different supervised learning algorithms suit different problems.
Linear regression is simple and interpretable, ideal for predicting numerical values when relationships are roughly linear.
Logistic regression is widely used for binary classification—spam or not, fraud or not—and outputs probabilities.
Decision trees create a series of if-then rules learned from data, making them easy to visualize and explain.
Random forests combine many decision trees for higher accuracy, reducing the risk of overfitting.
Gradient boosting (like XGBoost) is often the top choice for structured data problems, winning many competitions.
Neural networks excel at complex patterns in unstructured data—images, text, audio—but require large datasets.
2.6 When to Use Supervised Learning
Supervised learning is the right choice when you have labeled data, a clear target you want to predict, patterns in the data that map inputs to outputs, and you need to make predictions on new, unseen examples.
2.7 Advantages and Limitations
The strengths of supervised learning are clear: it can achieve high accuracy when sufficient labeled data is available, performance metrics are well-understood, and predictions are often interpretable—especially with simpler models.
The limitations are equally important. Supervised learning requires large amounts of labeled data, and labeling is expensive and time-consuming. Models only learn what is in the training data—they cannot discover new categories or patterns outside what they were shown. And if the training data is biased, the model will be too.
Section 3: Unsupervised Learning—Finding Patterns Without Labels
3.1 What Is Unsupervised Learning?
Unsupervised learning finds patterns, structures, and relationships in data without any labeled answers. The algorithm explores the data and discovers hidden structures on its own.
Think of it as exploring a new city without a map. You do not have labeled landmarks, but you notice patterns—which neighborhoods have similar architecture, which streets have more foot traffic, which areas are connected.
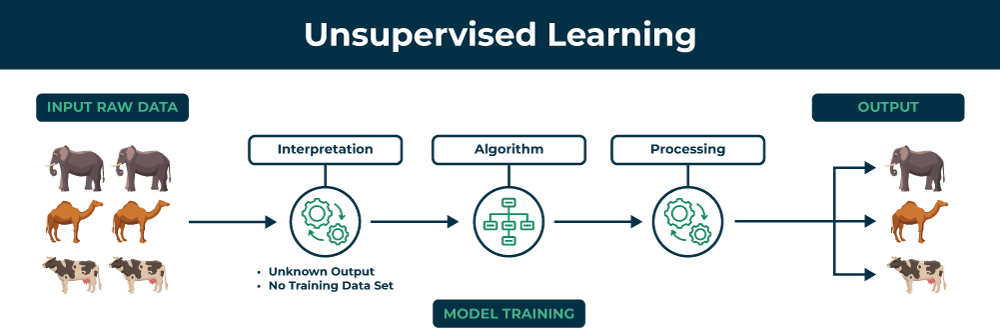
3.2 How Unsupervised Learning Works
Unlike supervised learning, there is no “correct answer” to compare against. The algorithm looks for natural structures in the data. It might find clusters—groups of similar examples. It might discover associations—patterns that frequently co-occur. It might identify anomalies—examples that are unusual. Or it might find latent structure—underlying factors that explain the data.
3.3 Main Types
Clustering groups similar examples together. Customer segmentation, document clustering, and image grouping all use clustering.
Association rule learning finds patterns that co-occur. Market basket analysis—“people who buy diapers also buy baby wipes”—is the classic example.
Dimensionality reduction compresses data while preserving structure. This is useful for visualizing high-dimensional data or speeding up other algorithms.
Anomaly detection identifies unusual examples—fraud detection, manufacturing defects, network intrusion.
3.4 Real-World Examples
Customer segmentation uses clustering to group customers by purchasing behavior without any pre-existing labels. A retailer might discover segments like “budget-conscious families,” “luxury shoppers,” and “frequent small purchases.” Each segment then gets tailored marketing.
Market basket analysis finds products frequently bought together. An online retailer learns that customers who buy running shoes often buy moisture-wicking socks. This insight drives product recommendations and store layouts.
Document clustering groups news articles by topic without pre-labeled categories. A news aggregator automatically organizes articles into topics like politics, sports, and technology.
Fraud detection uses anomaly detection to identify transactions that look different from normal patterns. The model flags unusual activity for review, even without prior examples of fraud.
Genomics research uses clustering to group genes with similar expression patterns, helping researchers understand which genes work together.
3.5 Common Algorithms
K-Means clustering partitions data into a specified number of groups. It is fast and widely used for customer segmentation and image compression.
Hierarchical clustering creates a tree of clusters, showing relationships at different levels of granularity.
DBSCAN finds clusters of arbitrary shapes based on density, useful when the number of clusters is not known in advance.
Apriori and similar algorithms find frequent itemsets for market basket analysis.
Principal Component Analysis (PCA) compresses data while preserving variance, often used as a preprocessing step.
t-SNE and UMAP visualize high-dimensional data in 2D or 3D, revealing hidden structures.
3.6 When to Use Unsupervised Learning
Unsupervised learning is the right choice when you have no labels—labeled data is unavailable, expensive, or impractical. It is ideal for exploration when you do not know what patterns exist. Use it when you need structure—to group, compress, or understand your data—or when you need to detect anomalies.
3.7 Advantages and Limitations
The biggest advantage of unsupervised learning is that it requires no labeled data, avoiding expensive and time-consuming labeling. It can discover unexpected patterns that humans might not have considered. It is useful for exploration and hypothesis generation, and it scales to large, unlabeled datasets.
The limitations are significant. Results can be subjective—there is no clear “correct” answer to validate against. Interpretation requires domain expertise; the algorithm may find patterns that are not meaningful. Evaluation is challenging, and different algorithms or parameters can produce very different results.
Section 4: Reinforcement Learning—Learning Through Trial and Error
4.1 What Is Reinforcement Learning?
Reinforcement learning is a different paradigm. An agent learns to make decisions by interacting with an environment, receiving rewards or punishments for its actions. The goal is to maximize cumulative reward over time.
Think of it as training a dog with treats. The dog tries actions, gets rewards for good behavior, and learns which actions lead to treats. Over time, it learns sequences of actions that produce the best outcomes.
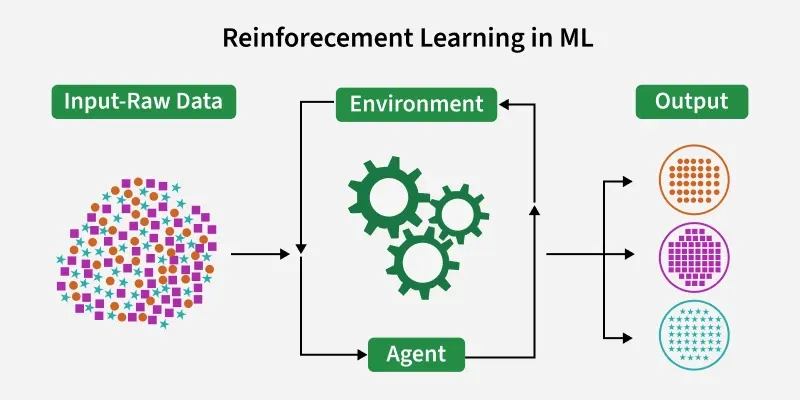
4.2 How Reinforcement Learning Works
The reinforcement learning loop is simple. The agent observes the current state of the environment. It takes an action. The environment transitions to a new state and provides a reward—positive for good actions, negative for bad ones. The agent updates its strategy (called a policy) based on the reward. Then the loop repeats.
The agent learns through exploration (trying new actions to discover their effects) and exploitation (using what it has learned to maximize reward). Over many episodes, it discovers sequences of actions that lead to high cumulative rewards.
4.3 Key Concepts
The agent is the learner or decision-maker—the AI system. The environment is the world the agent interacts with—a game, a simulation, a physical system. The state is the current situation at any moment. The action is what the agent can do. The reward is the feedback signal—positive, negative, or zero—that tells the agent whether an action was good. The policy is the agent’s strategy—what action to take in each state.
4.4 Real-World Examples
Game-playing AI like AlphaGo learned to play Go by playing millions of games against itself. It received a reward only at the end—win or lose—and had to figure out which moves along the way led to victory. It discovered novel strategies that no human had ever conceived.
Autonomous driving systems learn to navigate by simulating driving scenarios. The reward structure might give points for safe driving, smooth lane changes, and reaching destinations quickly, with penalties for collisions or traffic violations.
Robotics uses reinforcement learning to teach robots to grasp objects. The robot tries different grips, receives rewards for successful grasps, and learns over thousands of attempts to handle objects of varying shapes and materials.
Resource management systems learn to allocate computing resources, network bandwidth, or energy storage. Rewards reward efficient use and penalties discourage waste or overload.
Personalized recommendation systems increasingly use reinforcement learning to optimize long-term engagement, learning that showing a clickbait video today might hurt user retention tomorrow.
4.5 Common Algorithms
Q-Learning is a foundational algorithm that learns the value of taking actions in different states. Deep Q-Networks (DQN) combine Q-learning with deep neural networks to handle complex environments like video games.
Policy gradient methods learn policies directly, without estimating values first. They work well for continuous action spaces like robotics.
Proximal Policy Optimization (PPO) is a stable, widely used algorithm that balances exploration and exploitation effectively. It powers many modern reinforcement learning applications.
AlphaZero combines deep learning with Monte Carlo tree search to achieve superhuman performance in Go, chess, and shogi.
4.6 When to Use Reinforcement Learning
Reinforcement learning is the right choice when you have a sequential decision problem where actions today affect future outcomes. You need to be able to define rewards—even if you do not know the optimal path, you can give feedback. You need a simulation environment because real-world training requires millions of trials. And the problem involves strategy—not just pattern recognition but planning and adaptation.
4.7 Advantages and Limitations
The strengths of reinforcement learning are unique. It can discover strategies not known to humans, learning from scratch without expert examples. It learns optimal sequences, not just single predictions. It works for problems where labeled data is not available but feedback is. And it can operate in dynamic, changing environments.
The limitations are substantial. Reinforcement learning requires enormous amounts of training—millions of episodes. It needs a simulation environment, which is often not available for real-world problems. Reward design is challenging; poorly designed rewards lead to unintended behavior—the agent may find clever ways to game the reward system. And evaluation is difficult; performance can vary wildly between runs.
Section 5: How to Choose the Right Approach
5.1 A Decision Framework
Choosing the right machine learning approach starts with your problem and your data.
If you have labeled data and you know exactly what you want to predict, supervised learning is the natural choice. This covers the majority of business applications—fraud detection, demand forecasting, customer churn.
If you have unlabeled data and you want to explore structure, discover patterns, or group examples, unsupervised learning is the answer. Customer segmentation, anomaly detection, and market basket analysis all fall here.
If you have a sequential decision problem with delayed feedback, you can simulate the environment, and the goal is maximizing long-term reward, reinforcement learning is the appropriate approach. Game-playing, robotics, and process optimization are classic use cases.
5.2 Combining Approaches
Many real-world AI systems combine multiple approaches. Self-driving cars use supervised learning for object detection—identifying pedestrians and traffic signs. They use reinforcement learning for driving policy—when to change lanes, how to navigate intersections. And they use unsupervised learning for anomaly detection—spotting unusual road conditions.
Recommendation systems use supervised learning to predict clicks, unsupervised learning to segment users, and reinforcement learning to optimize long-term engagement.
Healthcare AI uses supervised learning for diagnosis, unsupervised learning for patient clustering, and reinforcement learning for treatment planning.
5.3 Common Mistakes to Avoid
Using supervised learning without labeled data is impossible—you need labels. If you do not have them, consider unsupervised learning or reinforcement learning instead.
Using reinforcement learning when you can use supervised learning is inefficient. If you have labeled expert examples, supervised learning will be faster and more stable.
Assuming unsupervised learning will produce actionable insights automatically is a mistake. Results require interpretation and domain expertise. The algorithm may find patterns that are statistically interesting but not business-relevant.
Underestimating the data requirements is common. Supervised learning needs thousands to millions of labeled examples. Reinforcement learning needs millions of simulation episodes. Unsupervised learning needs sufficient data for patterns to be statistically meaningful.
Section 6: How MHTECHIN Helps You Choose and Implement the Right Approach
Selecting the right machine learning approach is critical—the wrong choice leads to wasted effort and disappointing results. MHTECHIN helps organizations navigate this decision and implement solutions that deliver value.
6.1 For Strategy and Planning
MHTECHIN helps organizations assess their problem—is it classification, prediction, discovery, or sequential decision-making? They evaluate your data—do you have labeled data, unlabeled data, or the ability to simulate? They define success metrics that align with business goals. And they recommend the right approach—supervised, unsupervised, reinforcement, or a hybrid.
6.2 For Supervised Learning Implementation
MHTECHIN builds supervised learning systems for classification—spam detection, fraud detection, customer churn, medical diagnosis. For regression—demand forecasting, price prediction, risk scoring. For ranking—search relevance, recommendation ordering.
6.3 For Unsupervised Learning Implementation
MHTECHIN deploys unsupervised learning for customer segmentation to enable targeted marketing, anomaly detection to identify fraud or defects, market basket analysis to discover product associations, and data exploration to understand structure in large, unlabeled datasets.
6.4 For Reinforcement Learning Implementation
MHTECHIN implements reinforcement learning for process optimization in manufacturing, logistics, and resource allocation. For autonomous systems like robotics and drone navigation. For game-playing and simulation to discover strategies. And for personalization to optimize long-term engagement.
6.5 The MHTECHIN Approach
MHTECHIN’s machine learning practice is grounded in matching approach to problem. The team understands your business goals, evaluates your data and environment, recommends the appropriate approach, and then implements, tests, and iterates to deliver measurable value.
For organizations exploring machine learning, MHTECHIN provides the expertise to choose the right path—and execute it effectively.
Section 7: Frequently Asked Questions
7.1 Q: What is the difference between supervised and unsupervised learning?
A: Supervised learning uses labeled data—examples with correct answers—to learn how to predict outputs from inputs. Unsupervised learning uses unlabeled data to find patterns, clusters, or structures without any answer key.
7.2 Q: What is reinforcement learning used for?
A: Reinforcement learning is used for sequential decision-making problems where actions today affect future outcomes. Examples include game-playing AI, autonomous driving, robotics, resource management, and process optimization.
7.3 Q: Which approach is most common in business?
A: Supervised learning is the most widely used in business applications—spam detection, fraud detection, churn prediction, demand forecasting. It works well when historical labeled data is available.
7.4 Q: Can I use unsupervised learning without labeled data?
A: Yes—that is the point. Unsupervised learning is designed for exploring unlabeled data. It is useful for customer segmentation, anomaly detection, and understanding data structure when labels are unavailable.
7.5 Q: How much data do I need for supervised learning?
A: It depends on the complexity of the problem and the model. Simple classification may need thousands of examples. Deep learning for images may need hundreds of thousands. For many business problems, thousands to tens of thousands of labeled examples is sufficient.
7.6 Q: How does reinforcement learning train without labeled data?
A: Reinforcement learning learns from rewards, not labels. The agent takes actions, receives feedback (rewards or penalties), and learns to maximize cumulative reward over time. It discovers strategies through trial and error, not by imitating labeled examples.
7.7 Q: Can I combine multiple approaches?
A: Yes. Many real-world systems combine supervised learning for perception, unsupervised learning for pattern discovery, and reinforcement learning for decision-making. The choice depends on the problem.
7.8 Q: Which approach is easiest to start with?
A: For most beginners, supervised learning is the most straightforward because the goals are clear and evaluation is objective. Unsupervised learning requires more interpretation. Reinforcement learning requires simulation environments and significant compute.
7.9 Q: What is semi-supervised learning?
A: Semi-supervised learning combines a small amount of labeled data with a large amount of unlabeled data. It is useful when labeling is expensive but unlabeled data is abundant.
7.10 Q: How does MHTECHIN help with machine learning approach selection?
A: MHTECHIN helps organizations assess their problem, evaluate their data, and recommend the appropriate approach—supervised, unsupervised, reinforcement, or hybrid. We then implement solutions that deliver measurable business value.
Section 8: Conclusion—Matching Approach to Problem
Supervised learning, unsupervised learning, and reinforcement learning are not competitors—they are tools for different jobs. Supervised learning excels when you have labeled data and a clear prediction goal. Unsupervised learning shines when you need to discover structure in unlabeled data. Reinforcement learning is unmatched for sequential decision-making problems where actions have long-term consequences.
The key is not to ask which approach is “best,” but which is right for your problem. A business that needs to forecast sales needs supervised learning. A business that wants to understand customer segments needs unsupervised learning. A business optimizing a complex process with delayed feedback may need reinforcement learning.
For organizations building AI, the path forward is clear: understand your problem, evaluate your data, and choose the approach that fits. With the right foundation, machine learning can deliver powerful results.
Ready to choose the right machine learning approach for your business? Explore MHTECHIN’s AI advisory and implementation services at www.mhtechin.com. From strategy through deployment, our team helps you match approach to problem—and deliver results.
This guide is brought to you by MHTECHIN—helping organizations navigate machine learning, from supervised to unsupervised to reinforcement. For personalized guidance on ML strategy or implementation, reach out to the MHTECHIN team today.
Leave a Reply