Introduction
You have heard the term “neural network” countless times. It is invoked to explain everything from ChatGPT’s conversational abilities to facial recognition on your phone. But what actually is a neural network? For many professionals outside the technical field, the term remains vague—associated with brains, complexity, and a vague sense of “magic.”
The truth is, neural networks are not magic. They are a mathematical technique inspired by the brain, but they operate in ways that can be understood without a computer science degree. And in 2026, neural networks—especially deep learning—power the most transformative AI applications across healthcare, finance, customer service, and creative industries.
This article explains neural networks in simple, non-technical language. We will use analogies, real-world examples, and clear visual thinking to help you understand what they are, how they learn, and why they matter. Whether you are a business leader evaluating AI investments, a professional looking to collaborate with technical teams, or simply a curious learner, this guide will give you a solid mental model of neural networks.
For a foundational understanding of how AI, machine learning, and deep learning relate, you may find our guide on Machine Learning vs Deep Learning vs AI: Key Differences helpful as a starting point.
Throughout, we will highlight how MHTECHIN helps non-technical professionals and organizations understand and work with neural network-based AI systems.
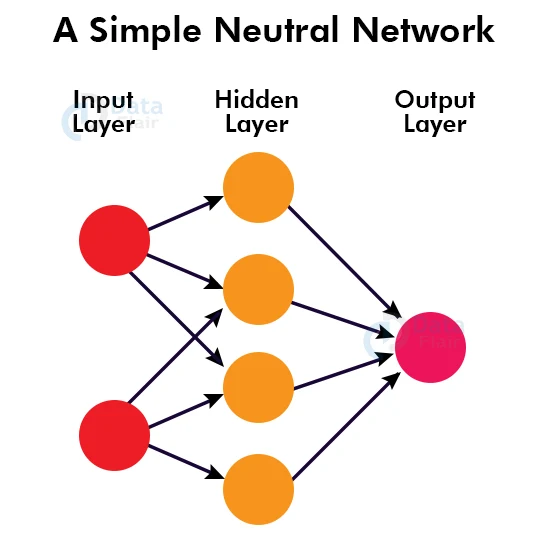
Section 1: What Is a Neural Network? A Simple Analogy
1.1 The Expert Panel Analogy
Imagine you need to determine whether an email is spam. Instead of writing rules, you assemble a panel of 1,000 experts. Each expert has a different opinion, but you give each expert a “vote weight.” Some experts are more trusted than others.
You show each expert the email. Some notice certain words, others look at the sender, others examine the formatting. Each expert gives a simple yes/no vote. You multiply each vote by the expert’s weight and sum them up. If the weighted total passes a threshold, you mark the email as spam.
Now, here is the crucial part: the experts learn. Initially, their weights are random, so their collective decision is poor. But after each decision, you check the actual answer. If the panel was wrong, you slightly adjust the weights—giving more influence to experts who were right and less to those who were wrong. Over thousands of emails, the panel gets better and better.
That is essentially what a neural network does. The “experts” are artificial neurons. The “weights” are numbers that get adjusted during learning. The process of adjusting weights based on mistakes is called training.
1.2 The Brain Inspiration
Neural networks are loosely inspired by the human brain. In the brain, neurons receive signals from other neurons through connections called synapses. When signals reach a threshold, the neuron fires, sending signals to other neurons.
Artificial neural networks use a simplified version of this idea. A neuron receives inputs, multiplies each by a weight, sums them, and if the sum exceeds a threshold, it “fires” an output to the next layer.
But there is an important caveat: artificial neural networks are inspired by the brain, not a replica of how brains work. They are a mathematical technique that happens to be effective for certain types of problems.
1.3 Why Neural Networks Are Powerful
Neural networks excel at problems that are difficult to solve with traditional rules:
- Recognizing objects in images—no one can write rules for “cat-ness”
- Understanding spoken language—accents, context, ambiguity
- Translating between languages—subtle grammar and meaning
- Predicting complex patterns—customer behavior, disease risk, market trends
They are not the right tool for every problem. But for problems involving unstructured data—images, audio, text—neural networks are the dominant approach.
Section 2: The Building Blocks—Artificial Neurons
2.1 The Single Neuron
A single artificial neuron (also called a perceptron) is a simple mathematical function. It takes several inputs, multiplies each by a weight, adds them together, and then applies an activation function to produce an output.
Think of it as a simple formula:
*Output = Activation( (Input1 × Weight1) + (Input2 × Weight2) + … + (InputN × WeightN) )*
The activation function is a threshold-like rule: if the sum is high enough, the neuron “fires” (outputs a positive value); if not, it stays quiet (outputs near zero).
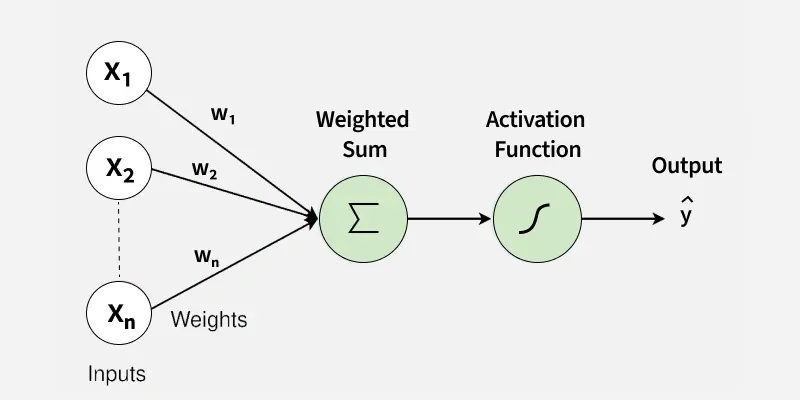
2.2 What Do the Numbers Mean?
For a non-technical professional, the key insight is that weights are learned from data. You do not program the neuron with rules; you show it examples, and it gradually adjusts its weights to get better at the task.
Think of weights as “importance factors.” In a spam filter, one neuron might learn to pay close attention to the presence of certain words. Another might learn to weigh sender reputation heavily. The network figures out what matters through trial and error.
2.3 From One Neuron to Many
A single neuron is too simple for complex tasks. A single neuron can only learn linear patterns—like drawing a straight line to separate two categories. Real-world problems require curved, complex boundaries.
The solution is to connect many neurons together in layers. This is what turns a simple perceptron into a neural network.
Section 3: How Neural Networks Are Structured
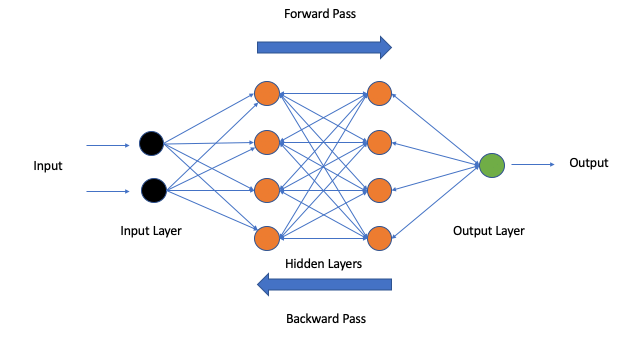
3.1 Layers: Input, Hidden, Output
A neural network is organized into layers:
Input Layer. This is where data enters the network. For an image, each input neuron might represent a pixel’s brightness. For a text model, inputs might represent words or parts of words. The number of input neurons matches the complexity of the data.
Hidden Layers. These are the layers between input and output. This is where the network does its learning. Hidden layers transform the raw input into increasingly abstract representations. A network can have one hidden layer (shallow) or dozens or hundreds (deep).
Output Layer. This produces the final result. For a spam classifier, the output might be a single neuron that outputs “spam probability.” For an image classifier with 1,000 categories, the output layer would have 1,000 neurons, each representing a category.
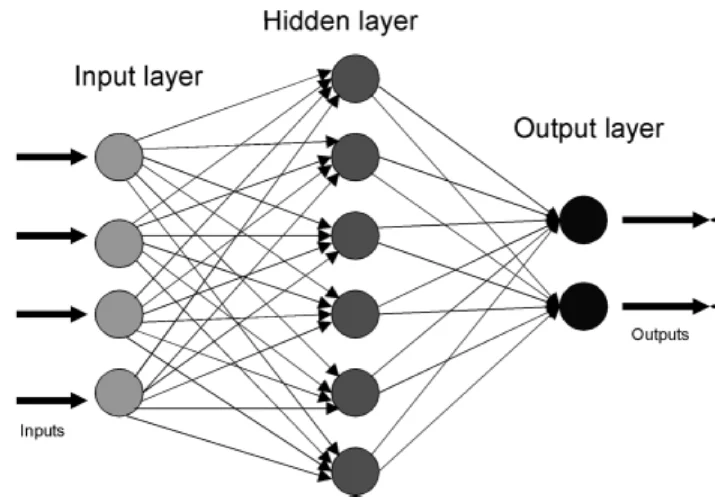
3.2 Deep vs. Shallow Neural Networks
A “deep” neural network is simply one with many hidden layers. Depth matters because each layer can learn increasingly abstract patterns.
Consider facial recognition:
- First hidden layer: detects edges and simple patterns (horizontal lines, vertical lines, corners)
- Second hidden layer: combines edges into features (eyes, nose, mouth outlines)
- Third hidden layer: assembles features into facial components (complete eyes, complete nose)
- Deeper layers: recognize whole faces, then specific identities
This hierarchical learning is why deep networks excel at complex tasks. Shallow networks (one or two hidden layers) work well for simpler problems but cannot capture the same level of abstraction.
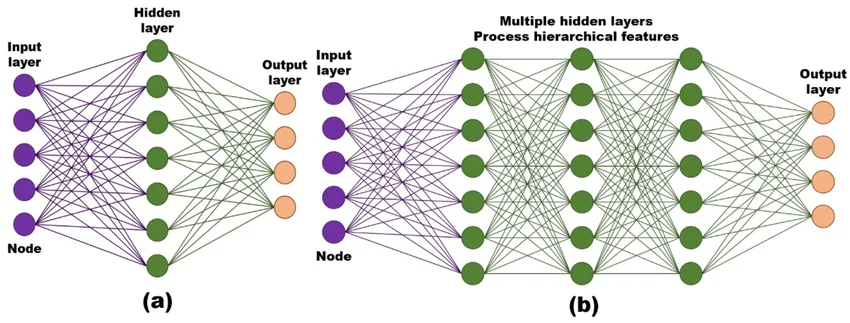
3.3 The “Black Box” Challenge
One limitation of neural networks—especially deep ones—is that they are difficult to interpret. You cannot easily look inside and see why the network made a particular decision.
This is sometimes called the “black box” problem. For many applications (like recommending movies), this is acceptable. But for regulated industries (like healthcare or lending), interpretability matters. This is why simpler machine learning models (like decision trees) are sometimes preferred when explainability is critical.
Section 4: How Neural Networks Learn—The Training Process
4.1 Training as Trial and Error
Neural networks learn through a process of trial and error, repeated millions of times. Here is how it works:
Step 1: Forward Pass. You feed the network an example (say, an image of a cat). The network processes it through all layers and produces an output. Initially, because the weights are random, the output is wrong—it might say “dog.”
Step 2: Calculate Error. You compare the network’s output to the correct answer. The difference is the error.
Step 3: Backward Pass (Backpropagation). You calculate how much each weight contributed to the error. Weights that caused the error are reduced slightly; weights that would have led to the correct answer are increased.
Step 4: Update Weights. You adjust all the weights by tiny amounts to reduce the error.
Step 5: Repeat. You do this again with another example. And another. And another. Millions of times.
Over time, the network’s weights converge on patterns that work well across many examples.
4.2 The Analogy: Learning to Throw Darts
Imagine learning to throw darts. Initially, your aim is random. You throw, see where the dart lands, and adjust your aim slightly. If it went left, you aim right. If it went high, you aim lower. After thousands of throws, you develop muscle memory that lands darts near the bullseye consistently.
Neural network training is similar. Each example is a throw. Each adjustment is a tiny correction. After millions of examples, the network develops “muscle memory”—weights that reliably produce correct outputs.
4.3 Data, Data, Data
Neural networks require enormous amounts of data. A large language model like ChatGPT is trained on trillions of words—the equivalent of reading the entire internet many times over.
Why so much data? Because neural networks have millions or billions of weights to adjust. Each weight needs many examples to converge on the right value. More complex networks (with more layers and neurons) require more data.
This is why deep learning is not suitable for every problem. If you only have a few thousand examples, simpler machine learning algorithms will often perform better.
4.4 The Role of Feedback
The quality of training depends on the quality of feedback. For supervised learning, this means having correct labels—every cat image must be labeled “cat.” For reinforcement learning (like AlphaGo), feedback comes from winning or losing games. For language models, feedback comes from human evaluators ranking responses (RLHF—reinforcement learning from human feedback).
This human feedback is what makes modern chatbots helpful, harmless, and honest.
Section 5: Types of Neural Networks and What They Do
5.1 Feedforward Neural Networks
The simplest type. Information flows in one direction—from input to output, no loops. These are used for basic classification and prediction tasks where the data has no inherent sequence or structure.
5.2 Convolutional Neural Networks (CNNs)
CNNs are designed for grid-like data—images, video, and sometimes audio spectrograms. Instead of connecting every neuron to every input (which would be enormous), CNNs slide small filters across the data, detecting local patterns like edges and textures.
CNNs power facial recognition, medical imaging AI, self-driving car vision, and any application that needs to understand visual information.
5.3 Recurrent Neural Networks (RNNs) and LSTMs
These networks have loops that allow information to persist. They are designed for sequences—time series, text, audio. An RNN maintains a “memory” of previous inputs, which helps it understand context.
Today, most sequence tasks (like language) use more advanced architectures (transformers), but RNNs and LSTMs are still used for time-series forecasting, speech recognition, and applications where order matters.
5.4 Transformers
Transformers are the architecture behind today’s most advanced language models—ChatGPT, Gemini, Claude. They introduced the attention mechanism, which allows the network to weigh the importance of different words when making predictions.
For example, in “She gave her dog a treat because it was hungry,” attention helps the network understand that “it” refers to “dog,” not “she.” Transformers can track these relationships across long passages of text, which is why they excel at language understanding and generation.
5.5 Diffusion Models
Diffusion models power modern image generators like Midjourney and DALL·E. They learn by gradually adding noise to images until they become pure static, then learning to reverse the process. Starting from random noise, they iteratively remove noise, guided by a text prompt, to create entirely new images.
5.6 Generative Adversarial Networks (GANs)
GANs use two networks—a generator and a discriminator—that compete against each other. The generator creates fake images; the discriminator tries to spot fakes. Over time, the generator becomes so good that the discriminator cannot tell real from fake. GANs are used for creating realistic faces, art, and synthetic data.
Section 6: Real-World Examples of Neural Networks in Action
6.1 ChatGPT and Large Language Models
When you chat with ChatGPT, you are interacting with a transformer-based neural network with billions of parameters (weights). It has been trained on trillions of words from books, websites, and documents.
The network does not “understand” in the human sense. It has learned patterns—grammar, facts, reasoning structures, styles—by predicting next words. When you ask a question, it generates responses by predicting what words are most likely to follow based on your input and the patterns it has learned.
6.2 Facial Recognition on Your Phone
When you unlock your phone with your face, a convolutional neural network (CNN) is at work. The network has been trained on millions of face images, learning to extract unique features—distances between eyes, shape of the jawline, contours of the nose.
When you look at your phone, the camera captures an image. The CNN processes it, creates a mathematical representation (called an embedding), and compares it to the stored representation of your face. If they match within a threshold, the phone unlocks.
6.3 Medical Imaging AI
Hospitals use CNNs to analyze medical images—X-rays, MRIs, CT scans. The networks are trained on thousands of images labeled by expert radiologists, learning to spot subtle anomalies that might indicate cancer, fractures, or other conditions.
In many studies, these networks match or exceed human radiologists for specific screening tasks. They do not replace doctors but serve as a second pair of eyes, flagging areas that deserve closer attention.
6.4 Self-Driving Cars
A self-driving car uses multiple neural networks working together. CNNs process camera images to detect pedestrians, vehicles, lane markings, and traffic signs. Other networks process lidar and radar data. Separate models predict where moving objects will be in the next few seconds.
A planning network—often using reinforcement learning—determines the car’s actions: accelerate, brake, change lanes. All of this happens in milliseconds, repeated dozens of times per second.
6.5 Recommendation Engines
When Netflix suggests a show or Amazon recommends a product, neural networks are often involved. The network learns patterns from your viewing history, what you have rated highly, what similar users enjoyed, and even when and how you watch.
These networks are trained to predict what you will enjoy—not just what is popular. They learn complex relationships: perhaps fans of science fiction who also enjoy Korean dramas are likely to enjoy certain titles.
Section 7: Common Misconceptions About Neural Networks
7.1 “Neural Networks Work Like the Human Brain”
They are inspired by the brain, but the analogy is loose. Real neurons are far more complex, with chemical signaling, complex timing, and intricate structures. Artificial neural networks are simplified mathematical models. While they are powerful, they do not “think” like humans.
7.2 “Neural Networks Are Always the Best Approach”
Not true. For many problems, simpler machine learning algorithms work better. They require less data, run faster, and are easier to interpret. Deep learning is most valuable for unstructured data (images, audio, text) at massive scale.
7.3 “Neural Networks Are Perfectly Accurate”
No. Neural networks make mistakes. They can be fooled by adversarial examples (slight image modifications that cause misclassification). They can hallucinate—generating confident but false information. They reflect biases in their training data. Human oversight remains essential.
7.4 “You Can See How a Neural Network Decides”
Generally, no. Neural networks are difficult to interpret. While researchers have developed techniques to visualize what networks learn, understanding exactly why a network made a specific decision is often impossible. This “black box” problem is an active area of research.
7.5 “Neural Networks Will Become Self-Aware”
There is no evidence that scaling neural networks leads to consciousness or self-awareness. Neural networks are tools—mathematical functions that map inputs to outputs. They do not have desires, beliefs, or intentions.
Section 8: How MHTECHIN Helps Non-Technical Professionals Understand Neural Networks
For professionals outside the technical field, neural networks can seem intimidating. MHTECHIN bridges the gap, helping you understand enough to make informed decisions without needing to become a data scientist.
8.1 For Executives and Decision-Makers
MHTECHIN provides executive briefings that explain neural networks in business terms:
- What problems are well-suited for neural networks
- What data and infrastructure are required
- Realistic timelines and costs
- Risk factors—bias, hallucination, interpretability
- How to evaluate vendor claims about “AI” and “neural networks”
8.2 For Non-Technical Professionals Working with Technical Teams
MHTECHIN’s workshops help professionals build enough literacy to collaborate effectively:
- How to communicate requirements to data science teams
- What questions to ask about model performance
- Understanding limitations and risks
- Setting realistic expectations for what neural networks can deliver
8.3 For Organizations Deploying Neural Network-Based Systems
MHTECHIN helps organizations navigate the full lifecycle:
- Assessing whether a problem is suited for neural networks or simpler ML
- Data readiness—do you have enough labeled data?
- Infrastructure—do you have the computing resources?
- Deployment—how to integrate neural networks into workflows
- Monitoring—how to track performance and detect drift
8.4 The MHTECHIN Difference
MHTECHIN’s approach is grounded in clear communication. The team understands that not everyone needs to be a deep learning engineer—but everyone who works with AI needs enough literacy to ask the right questions, set realistic expectations, and make informed decisions.
For individuals and organizations alike, MHTECHIN provides the guidance to navigate the neural network landscape—demystifying the technology without oversimplifying the challenges.
Section 9: Frequently Asked Questions
9.1 Q: What is a neural network in simple terms?
A: A neural network is a computer system inspired by the brain. It consists of many simple processing units (neurons) connected in layers. Instead of being programmed with rules, it learns from examples by adjusting the strength of connections between neurons. Through repeated exposure to data, it learns to recognize patterns and make predictions.
9.2 Q: How is a neural network different from traditional programming?
A: Traditional programming: you write explicit rules, and the computer follows them. Neural networks: you provide examples, and the network discovers its own rules. For tasks like recognizing faces, writing rules is impossible—neural networks learn the patterns from data.
9.3 Q: Why are they called “deep” neural networks?
A: “Deep” refers to the number of layers in the network. Shallow networks have one or two hidden layers. Deep networks have many hidden layers—sometimes dozens or hundreds. More layers allow the network to learn hierarchical representations, from simple patterns (edges) to complex concepts (faces).
9.4 Q: How do neural networks learn?
A: Neural networks learn through a process called backpropagation. They make a prediction, compare it to the correct answer, calculate the error, then work backward through the network to adjust each connection’s strength (weight) slightly. This is repeated millions of times with millions of examples until the network becomes accurate.
9.5 Q: Do neural networks understand what they are doing?
A: No. Neural networks do not have understanding, consciousness, or intent. They are mathematical functions that map inputs to outputs based on patterns learned from data. When ChatGPT generates text, it is predicting likely word sequences—not “thinking” about the meaning.
9.6 Q: How much data do neural networks need?
A: A large language model requires trillions of words—the equivalent of reading the entire internet many times. A facial recognition system may need millions of labeled face images. Simpler neural networks (fewer layers, fewer neurons) require less data. If you have limited data, simpler machine learning algorithms often work better.
9.7 Q: Can I see how a neural network makes decisions?
A: Generally, no. Neural networks are considered “black boxes.” While researchers have developed techniques to visualize what networks learn, understanding exactly why a specific decision was made is often impossible. This is an important consideration for regulated industries where explainability is required.
9.8 Q: What are the main types of neural networks?
A: Common types include: Convolutional Neural Networks (CNNs) for images; Recurrent Neural Networks (RNNs) and LSTMs for sequences; Transformers for language; Diffusion Models for image generation; and Generative Adversarial Networks (GANs) for creating realistic synthetic data.
9.9 Q: What hardware do neural networks require?
A: Training large neural networks requires specialized hardware—graphics processing units (GPUs) or tensor processing units (TPUs). These chips are designed for the massive parallel computations that neural networks require. Running a trained network (inference) is less demanding but still benefits from specialized hardware.
9.10 Q: How can I learn more about neural networks without a technical background?
A: Start with high-level resources that focus on concepts rather than math. MHTECHIN offers workshops designed for non-technical professionals that explain how neural networks work, what they are good for, and how to work with technical teams. Our guides on AI fundamentals and machine learning basics provide a solid foundation.
Section 10: Conclusion—Neural Networks as Tools, Not Magic
Neural networks are among the most powerful technologies of our time. They enable systems that understand speech, recognize faces, translate languages, generate art, and even assist in scientific discovery. But they are not magic. They are mathematical tools—complex ones—that learn patterns from data through trial and error.
For non-technical professionals, the key is to understand enough to ask the right questions: What problem are we solving? Do we have enough data? Is interpretability important? What are the risks? With this understanding, you can make informed decisions about when and how to use neural networks—and when simpler approaches are better.
The organizations that succeed with AI are not necessarily those with the most advanced neural networks, but those that understand the technology’s strengths and limitations—and match the approach to the problem.
Ready to understand neural networks with confidence? Explore MHTECHIN’s workshops and advisory services at www.mhtechin.com. From executive briefings to hands-on training, our team helps non-technical professionals navigate the AI landscape.
This guide is brought to you by MHTECHIN—helping non-technical professionals understand and work with neural networks and AI systems. For personalized guidance on AI literacy or technology strategy, reach out to the MHTECHIN team today.
Leave a Reply