Introduction
You have a large language model. It is powerful, but it does not know your specific domain. It was trained on public internet text—not your internal documents, not your product catalog, not your customer support history. You need it to understand your world. How do you make that happen?
Two approaches dominate the conversation: fine-tuning and retrieval-augmented generation (RAG) . Both can adapt general-purpose models to specific domains. Both have passionate advocates. But they work in fundamentally different ways, and choosing between them—or combining them—is one of the most important decisions in building production AI systems.
This article explains what fine-tuning and RAG are, how they work, when to use each, and how to combine them for maximum effect. Whether you are a developer building AI applications, a data scientist optimizing models, or a business leader making technology decisions, this guide will help you understand the trade-offs.
For a foundational understanding of how embeddings and retrieval work, you may find our guide on AI Embeddings: Turning Text into Numbers for Search and Retrieval helpful as a starting point.
Throughout, we will highlight how MHTECHIN helps organizations choose and implement the right approach—or combination—for their specific needs.
Section 1: What Is Fine-Tuning?
1.1 A Simple Definition
Fine-tuning is the process of taking a pre-trained language model and continuing its training on a smaller, domain-specific dataset. The model’s internal weights are updated to become more proficient at tasks related to that domain.
Think of it as specialized education. A general-purpose model has read the entire internet—it is broadly knowledgeable but not expert in anything. Fine-tuning gives it focused training in your domain, adjusting its internal knowledge to better serve your needs.
1.2 How Fine-Tuning Works
The process follows these steps:
- Start with a base model. A pre-trained model like GPT-4, Llama 3, or Mistral.
- Prepare your dataset. Collect examples of the behavior you want—question-answer pairs, instruction-response examples, or labeled data.
- Continue training. The model is trained further on your dataset, with a small learning rate to avoid overwriting general knowledge.
- Deploy the fine-tuned model. The updated model is now specialized for your domain.
Fine-tuning can be full (updating all model weights) or parameter-efficient (updating only a small subset of weights, like LoRA). Parameter-efficient fine-tuning is cheaper and faster, often yielding results nearly as good as full fine-tuning.
1.3 What Fine-Tuning Changes
Fine-tuning updates the model’s internal knowledge. After fine-tuning:
- Style and tone. The model learns to write in your company’s voice
- Domain terminology. The model learns your technical terms, product names, and internal jargon
- Task proficiency. The model gets better at your specific tasks (e.g., answering customer support questions)
- Structured outputs. The model learns to format responses according to your specifications
1.4 When Fine-Tuning Makes Sense
Fine-tuning is the right choice when:
- You have a consistent task. The model needs to perform the same type of task repeatedly
- You have labeled data. You have examples of the desired behavior (hundreds to thousands)
- Style and tone matter. You want the model to sound like your brand
- You need low latency. Fine-tuned models are just as fast as base models
- You operate at scale. Fine-tuning costs are upfront; per-inference costs remain the same
Section 2: What Is Retrieval-Augmented Generation (RAG)?
2.1 A Simple Definition
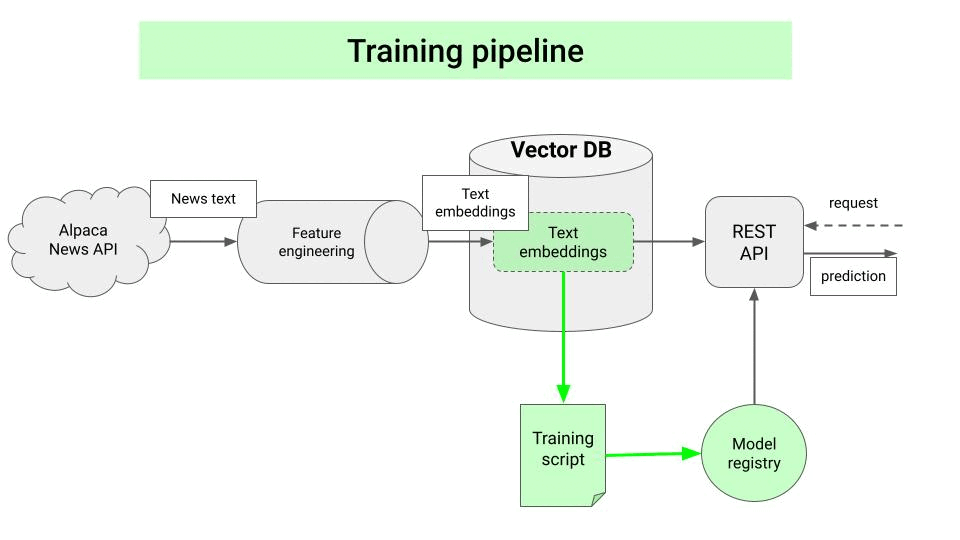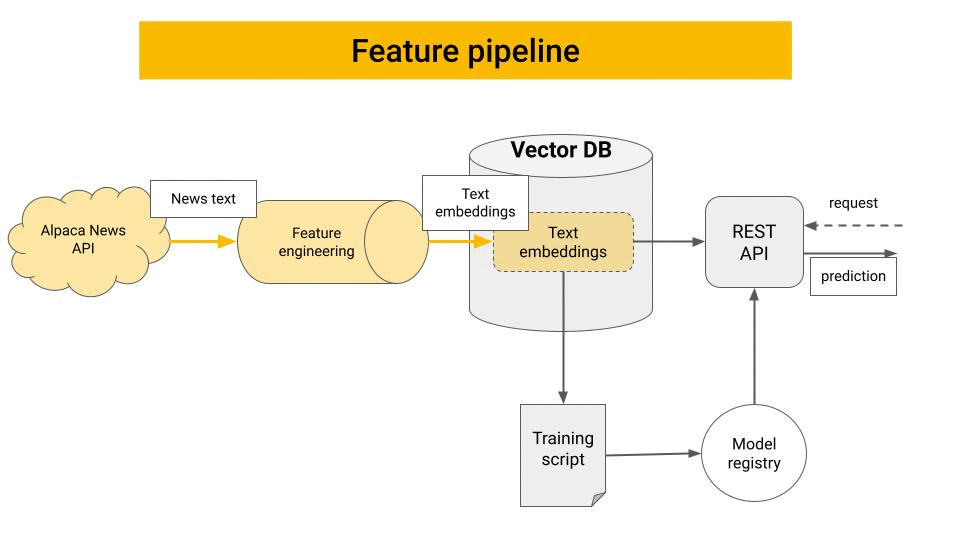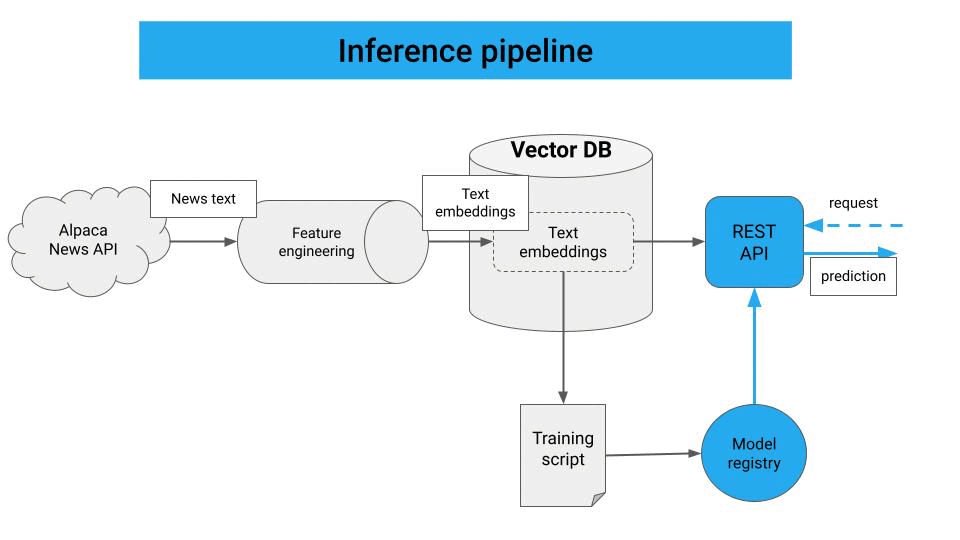
Retrieval-augmented generation (RAG) is a pattern where a language model is given access to external knowledge at inference time. Instead of relying solely on its internal parameters, it retrieves relevant information from a knowledge base and uses that information to generate responses.
Think of it as open-book versus closed-book. Fine-tuning is like studying for a test—the knowledge is internalized. RAG is like having a reference library available during the test—the model can look up information as needed.
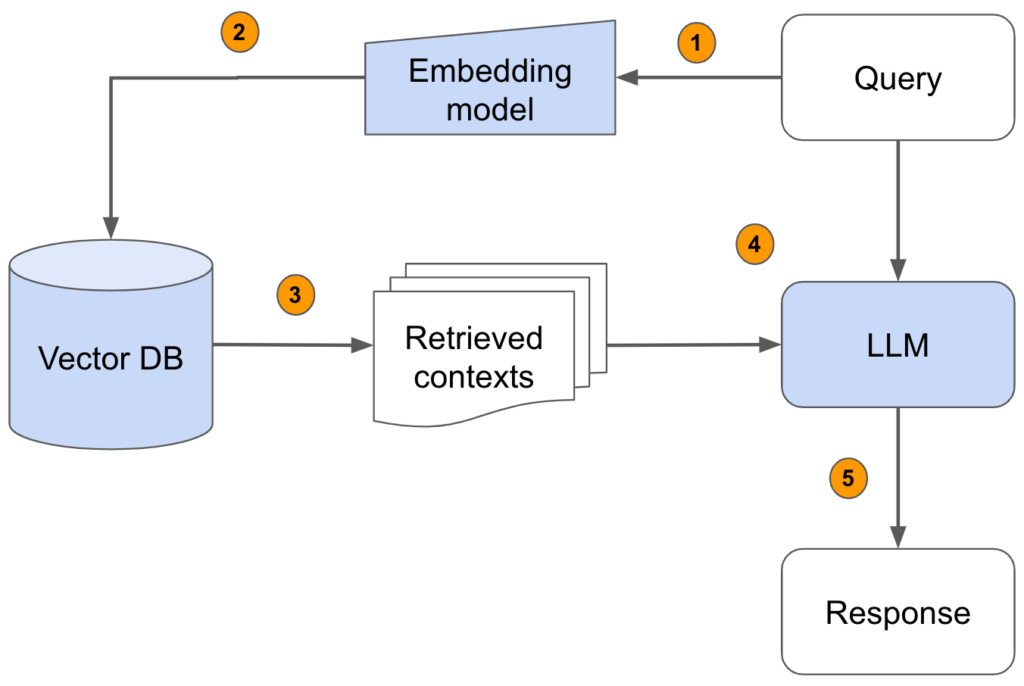
2.2 How RAG Works
The RAG process involves several steps:
- Prepare a knowledge base. Collect your documents, internal data, or domain-specific information.
- Chunk and embed. Split documents into manageable chunks and create embeddings (vector representations) for each chunk.
- Store in a vector database. Store the embeddings with references to the original content.
- At query time. User asks a question.
- Retrieve. The question is embedded and used to search for similar chunks in the vector database.
- Augment. Retrieved chunks are added to the prompt as context.
- Generate. The language model generates a response based on both the question and the retrieved context.
2.3 What RAG Provides
RAG gives the model access to:
- Up-to-date information. The knowledge base can be updated without retraining the model
- Private data. Sensitive documents never enter the model’s weights; they stay in your vector database
- Specific facts. Exact details, numbers, dates, and quotes can be retrieved and cited
- Attribution. The model can reference sources, enabling verification
2.4 When RAG Makes Sense
RAG is the right choice when:
- Your knowledge changes frequently. New documents, products, or policies are added regularly
- You need source attribution. You want to show where information came from
- You have a large, diverse knowledge base. The model does not need to internalize everything
- You cannot fine-tune. You lack labeled data or cannot afford fine-tuning
- Privacy is critical. Sensitive data should not be incorporated into model weights
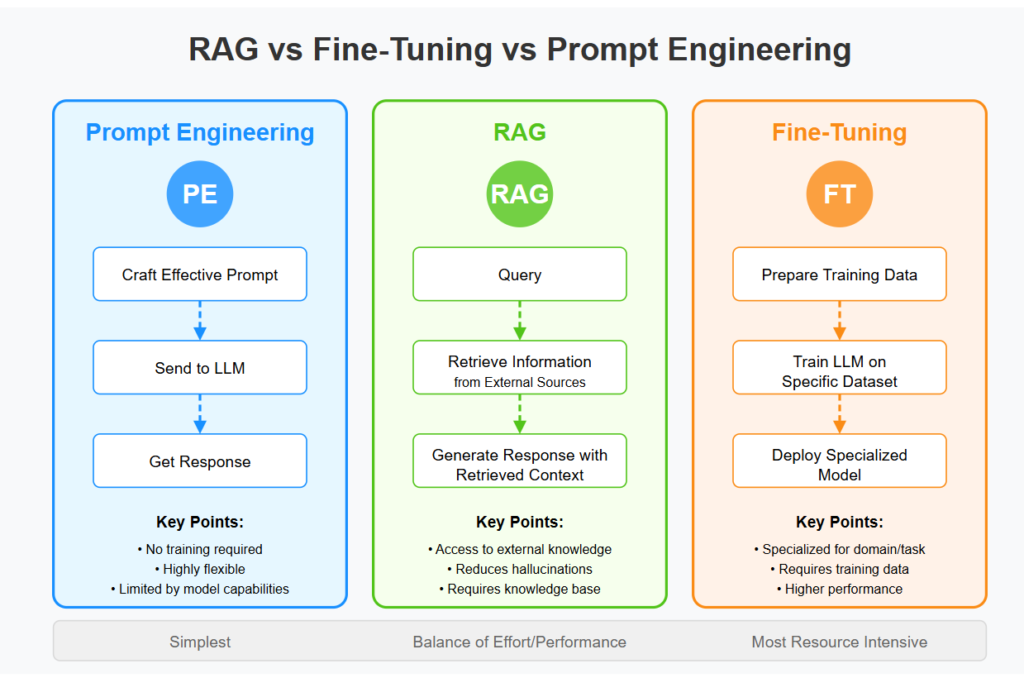
Section 3: Fine-Tuning vs RAG—Key Differences
3.1 Side-by-Side Comparison
| Dimension | Fine-Tuning | RAG |
|---|---|---|
| How it works | Updates model weights on domain data | Retrieves information at inference time |
| Knowledge source | Internalized into model parameters | External knowledge base (vector database) |
| Updates | Requires retraining to update knowledge | Update knowledge base instantly |
| Latency | Same as base model | Retrieval adds latency (milliseconds to seconds) |
| Cost | Upfront training cost; same inference cost | No training cost; retrieval + API costs |
| Data needs | Labeled examples (hundreds to thousands) | Unstructured documents (any volume) |
| Attribution | Difficult—knowledge is internalized | Easy—can cite retrieved sources |
| Hallucinations | Reduced but not eliminated | Significantly reduced with good retrieval |
| Style adaptation | Excellent—learns your tone | Limited—prompt engineering required |
| Domain terminology | Excellent—learns your terms | Good—terms appear in retrieved context |
3.2 The Knowledge Distinction
The fundamental difference is where knowledge lives:
- Fine-tuning internalizes knowledge into the model’s parameters. The model becomes the knowledge.
- RAG keeps knowledge external. The model retrieves what it needs at inference time.
This distinction drives most of the trade-offs.
3.3 When to Choose Fine-Tuning
Choose fine-tuning when:
- You have a consistent, stable knowledge domain (e.g., customer support for a product that changes rarely)
- You need low latency and cannot afford retrieval overhead
- You want the model to adopt a specific style, tone, or format
- You have labeled data (question-answer pairs, instructions)
- You operate at high scale where per-inference optimization matters
Example. A company fine-tunes a model on its customer support history. The model learns the company’s voice, common issues, and resolution patterns. Responses are fast and consistent.
3.4 When to Choose RAG
Choose RAG when:
- Your knowledge changes frequently (e.g., product catalog, pricing, policies)
- You need source attribution and auditability
- You have a large corpus of documents but no labeled data
- You cannot afford fine-tuning infrastructure
- You need to incorporate sensitive data that should not be in model weights
Example. A legal firm uses RAG to answer questions about case law. New rulings are added to the knowledge base instantly. The model cites specific cases and statutes.
Section 4: Combining Fine-Tuning and RAG
4.1 The Hybrid Approach
Fine-tuning and RAG are not mutually exclusive. In fact, the most powerful AI systems often combine both:
- Fine-tune for style and structure. Teach the model how to format responses, use your brand voice, and follow your interaction patterns.
- Use RAG for knowledge. The fine-tuned model retrieves current, specific information from a knowledge base.
This combination gives you the best of both worlds: the model knows how to communicate (from fine-tuning) and what to communicate (from RAG).
4.2 Why Hybrid Works
| Capability | Provided By |
|---|---|
| Brand voice and style | Fine-tuning |
| Response format | Fine-tuning |
| Up-to-date information | RAG |
| Private data | RAG |
| Source attribution | RAG |
| Domain terminology | Both (fine-tuning internalizes, RAG provides context) |
4.3 Use Cases for Hybrid
Customer Support. Fine-tune on historical support interactions to learn the company’s voice and common resolution patterns. Use RAG to retrieve current product documentation, pricing, and policies.
Healthcare. Fine-tune on medical terminology and clinical note formats. Use RAG to retrieve relevant patient history, recent studies, and treatment guidelines.
Enterprise Search. Fine-tune on company communication style and document formats. Use RAG to retrieve current documents, emails, and internal knowledge.
4.4 Implementation Considerations
When building a hybrid system:
- Fine-tune first. Establish the model’s base behavior—style, format, and task proficiency.
- Design retrieval. Build a vector database of your knowledge base. Optimize chunking and embedding.
- Integrate. Construct prompts that combine retrieved context with instructions.
- Test and iterate. Evaluate retrieval quality and generation quality together.
Section 5: Cost and Performance Trade-Offs
5.1 Cost Comparison
| Cost Factor | Fine-Tuning | RAG | Hybrid |
|---|---|---|---|
| Training | High (GPU hours) | None | High (fine-tuning) |
| Inference (per call) | Same as base model | API cost + retrieval | API cost + retrieval |
| Storage | Model weights | Vector database + documents | Both |
| Maintenance | Model versioning | Knowledge base updates | Both |
| Data preparation | Labeled examples | Document ingestion | Both |
5.2 Latency Comparison
| Scenario | Fine-Tuning | RAG | Hybrid |
|---|---|---|---|
| First token latency | Low | Medium (retrieval adds 100–500ms) | Medium |
| Throughput | High | Medium (vector search overhead) | Medium |
| Consistency | High | Variable (retrieval quality varies) | Variable |
5.3 Optimization Strategies
For fine-tuning:
- Use parameter-efficient fine-tuning (LoRA, QLoRA) to reduce training cost
- Start with smaller base models if sufficient for your task
- Cache responses for common queries
For RAG:
- Optimize vector database indexing (HNSW, IVF) for speed
- Cache embeddings for frequent queries
- Use smaller embedding dimensions where appropriate
- Implement hybrid search (keyword + vector) to improve retrieval
Section 6: Common Pitfalls and How to Avoid Them
6.1 Fine-Tuning Pitfalls
Pitfall: Overfitting to training data. The model memorizes examples rather than generalizing.
Avoid. Use a validation set, early stopping, and parameter-efficient methods. Include diverse examples.
Pitfall: Catastrophic forgetting. The model loses general capabilities while learning domain specifics.
Avoid. Use a small learning rate. Mix general data with domain data during fine-tuning.
Pitfall: Insufficient data. Fine-tuning with too few examples leads to poor generalization.
Avoid. Start with few-shot prompting before committing to fine-tuning. Ensure hundreds to thousands of high-quality examples.
6.2 RAG Pitfalls
Pitfall: Poor retrieval quality. Retrieved chunks are irrelevant, leading to bad generations.
Avoid. Optimize chunking, embedding model selection, and retrieval thresholds. Test retrieval quality independently.
Pitfall: Context overload. Too much retrieved context confuses the model or exceeds token limits.
Avoid. Limit retrieved chunks to the most relevant (3–5). Summarize or re-rank results.
Pitfall: Hallucinations despite retrieval. The model ignores retrieved context and relies on internal knowledge.
Avoid. Prompt engineering to emphasize using retrieved context. Consider fine-tuning for better instruction following.
6.3 Hybrid Pitfalls
Pitfall: Misaligned fine-tuning and retrieval. The fine-tuned model does not integrate well with retrieved context.
Avoid. Include retrieval examples in your fine-tuning data. Test the integrated system end-to-end.
Pitfall: Complexity overhead. Maintaining both fine-tuned models and vector databases adds operational burden.
Avoid. Start with RAG alone. Add fine-tuning only when needed. Use managed services where possible.
Section 7: How MHTECHIN Helps with Fine-Tuning and RAG
Choosing between fine-tuning and RAG—or combining them—requires expertise in both approaches. MHTECHIN helps organizations design and implement the right strategy for their specific needs.
7.1 For Strategy and Assessment
MHTECHIN helps organizations:
- Assess your use case. What tasks? What knowledge? How does it change?
- Evaluate your data. Do you have labeled examples? Unstructured documents?
- Estimate costs. Training vs. retrieval vs. hybrid
- Define success. Latency, accuracy, attribution requirements
7.2 For Fine-Tuning Implementation
MHTECHIN builds fine-tuned models:
- Data preparation. Curate and label training examples
- Model selection. Choose base model (open source or API)
- Fine-tuning. Full or parameter-efficient; optimize for your task
- Evaluation. Test on held-out data; compare to baseline
7.3 For RAG Implementation
MHTECHIN builds RAG pipelines:
- Knowledge base preparation. Document ingestion, chunking, embedding
- Vector database selection. pgvector, Pinecone, Weaviate, etc.
- Retrieval optimization. Index tuning, hybrid search, re-ranking
- LLM integration. Prompt engineering, context assembly
7.4 For Hybrid Systems
MHTECHIN designs hybrid architectures:
- Fine-tune for style, RAG for knowledge. Combine both approaches
- Unified evaluation. Test retrieval and generation together
- Operational pipelines. Manage both fine-tuned models and knowledge base updates
7.5 The MHTECHIN Approach
MHTECHIN’s approach is pragmatic: start with the simplest solution that meets your needs. Often, that is RAG—it is cheaper to start, easier to update, and provides attribution. Add fine-tuning when style, latency, or consistency requirements justify it. The team helps organizations navigate this decision and implement solutions that deliver real business value.
Section 8: Frequently Asked Questions
8.1 Q: What is the difference between fine-tuning and RAG?
A: Fine-tuning updates the model’s internal weights to learn domain-specific knowledge. RAG keeps knowledge external and retrieves relevant information at inference time. Fine-tuning is like studying for a test; RAG is like using open-book resources.
8.2 Q: Which is better: fine-tuning or RAG?
A: Neither is universally “better.” Fine-tuning excels for stable domains, style adaptation, and low latency. RAG excels for frequently changing knowledge, source attribution, and privacy. The best choice depends on your specific needs.
8.3 Q: Can I combine fine-tuning and RAG?
A: Yes. The most powerful systems often combine both: fine-tune for style and format, use RAG for up-to-date knowledge. This gives you the best of both approaches.
8.4 Q: How much data do I need for fine-tuning?
A: It depends on the task and model size. For parameter-efficient fine-tuning, hundreds to thousands of high-quality examples can be sufficient. For full fine-tuning, you may need more. Start with RAG if you have limited labeled data.
8.5 Q: How do I update knowledge with fine-tuning vs RAG?
A: Fine-tuning requires retraining the model—a process that takes time and compute. RAG updates are instant: just add or update documents in the knowledge base.
8.6 Q: Which reduces hallucinations more: fine-tuning or RAG?
A: RAG generally reduces hallucinations more effectively because the model has retrieved context to reference. However, if retrieval quality is poor, RAG can still hallucinate. Fine-tuning reduces hallucinations for domain-specific tasks but does not eliminate them.
8.7 Q: Which is more expensive: fine-tuning or RAG?
A: Fine-tuning has high upfront costs (training compute) but the same per-inference costs as the base model. RAG has no training costs but adds retrieval costs (vector database queries, embedding generation). At high scale, fine-tuning can be cheaper; at low scale, RAG is often cheaper.
8.8 Q: Does RAG require a vector database?
A: Yes, for efficient retrieval. Vector databases store embeddings and enable fast similarity search. For small-scale applications, you can use in-memory solutions like Chroma. For production, dedicated vector databases like Pinecone, Weaviate, or pgvector are recommended.
8.9 Q: Can I fine-tune a model for retrieval?
A: Yes. You can fine-tune embedding models to better represent your domain, improving retrieval quality. You can also fine-tune language models to better integrate retrieved context.
8.10 Q: How does MHTECHIN help with fine-tuning and RAG?
A: MHTECHIN helps organizations assess their needs, choose the right approach, and implement solutions—whether fine-tuning, RAG, or hybrid. We provide end-to-end support from strategy through deployment.
Section 9: Conclusion—Choose the Right Tool for the Job
Fine-tuning and RAG are not competitors. They are complementary tools for different problems.
Fine-tuning is about internalizing knowledge. It makes the model an expert in your domain, teaching it your style, terminology, and patterns. It is ideal when your knowledge is stable, you need low latency, and you have labeled data.
RAG is about accessing knowledge. It gives the model a library to consult, enabling it to work with up-to-date information, private data, and large document collections. It is ideal when knowledge changes frequently, you need source attribution, or you cannot fine-tune.
The most powerful AI systems combine both. They fine-tune models to understand how to communicate—and use RAG to determine what to say. This hybrid approach delivers the best of both worlds: consistent style, current knowledge, and verifiable sources.
For organizations building AI, the key is to understand your requirements, evaluate the trade-offs, and choose the approach—or combination—that fits. With clear strategy and the right expertise, you can build AI that truly understands your world.
Ready to choose the right approach for your AI? Explore MHTECHIN’s fine-tuning and RAG services at www.mhtechin.com. From strategy through implementation, our team helps you build intelligent systems that deliver.
This guide is brought to you by MHTECHIN—helping organizations navigate the fine-tuning vs RAG decision and implement solutions that work. For personalized guidance on AI strategy or implementation, reach out to the MHTECHIN team today.
Leave a Reply