1) Executive Overview
The landscape of artificial intelligence has undergone a fundamental transformation. Modern AI agents are no longer confined to simple question-answering or basic automation—they are now expected to reason, plan, analyze, and solve complex problems with human-like cognitive depth. This paradigm shift demands models specifically optimized for deep reasoning and structured thinking—capabilities that generic language models struggle to deliver consistently.
Claude 3.5 Sonnet, developed by Anthropic, has emerged as one of the most capable models in this category. Built on Anthropic’s constitutional AI framework and optimized for enterprise-grade reasoning, Claude 3.5 Sonnet represents a significant leap forward in AI’s ability to handle multi-step problem-solving, code generation, and long-context understanding.
At MHTECHIN, we specialize in building sophisticated AI agents that leverage Claude’s reasoning capabilities within enterprise architectures. This comprehensive guide explores how to design, implement, and scale complex reasoning agents using Claude 3.5 Sonnet, with actionable patterns, implementation blueprints, and real-world use cases.
2) Why Claude 3.5 Sonnet for Reasoning Agents?
The Reasoning Imperative
As organizations deploy AI agents for mission-critical tasks—from software engineering to financial analysis—the ability to reason accurately becomes non-negotiable. Claude 3.5 Sonnet distinguishes itself through a combination of architectural choices and training methodologies that prioritize structured thinking.
Key Strengths
| Capability | Description | Impact on Reasoning Agents |
|---|---|---|
| Long Context (200K+ tokens) | Handles entire codebases, lengthy documents, and multi-turn conversations in a single pass | Enables comprehensive understanding without fragmentation; agents can reason over entire codebases or extensive documentation |
| Structured Reasoning | Breaks down problems into logical steps; exhibits Chain-of-Thought naturally | Produces more accurate, traceable solutions; enables debugging of agent decision-making |
| Code Intelligence | Writes, debugs, and explains complex code across multiple languages | Powers autonomous software engineering agents; reduces development time |
| Safety & Alignment | Constitutional AI ensures controlled, predictable outputs | Critical for regulated industries; reduces hallucination risks |
| Tool Use | Native function calling with structured outputs | Enables agents to interact with APIs, databases, and external systems |
Performance Benchmarks
Independent evaluations consistently place Claude 3.5 Sonnet at the top for reasoning-intensive tasks:
- MATH benchmark: Outperforms comparable models on multi-step mathematical reasoning
- HumanEval: Demonstrates superior code generation and debugging capabilities
- DROP (Discrete Reasoning Over Paragraphs): Excels at complex reading comprehension and reasoning
3) What Are Complex Reasoning Agents?
Definition and Distinction
A complex reasoning agent is an AI system that goes beyond simple response generation to engage in structured cognitive processes. Unlike basic chatbots that provide direct answers, reasoning agents:
- Decompose problems into manageable sub-tasks
- Evaluate multiple solution paths before committing
- Apply logical frameworks to reach conclusions
- Iteratively refine outputs based on self-evaluation
- Maintain contextual awareness across extended interactions
Traditional Agent vs. Reasoning Agent
| Feature | Basic Agent | Reasoning Agent |
|---|---|---|
| Response Approach | Direct, single-pass | Step-by-step, iterative |
| Thinking Depth | Minimal or hidden | Explicit reasoning chains |
| Accuracy on Complex Tasks | Medium to Low | High |
| Explainability | Black box | Traceable logic |
| Error Recovery | Limited | Self-correction loops |
| Tool Integration | Simple API calls | Orchestrated multi-step tool use |
| Ideal Use Cases | Chatbots, simple Q&A | Analysis, coding, planning, research |
The Reasoning Spectrum
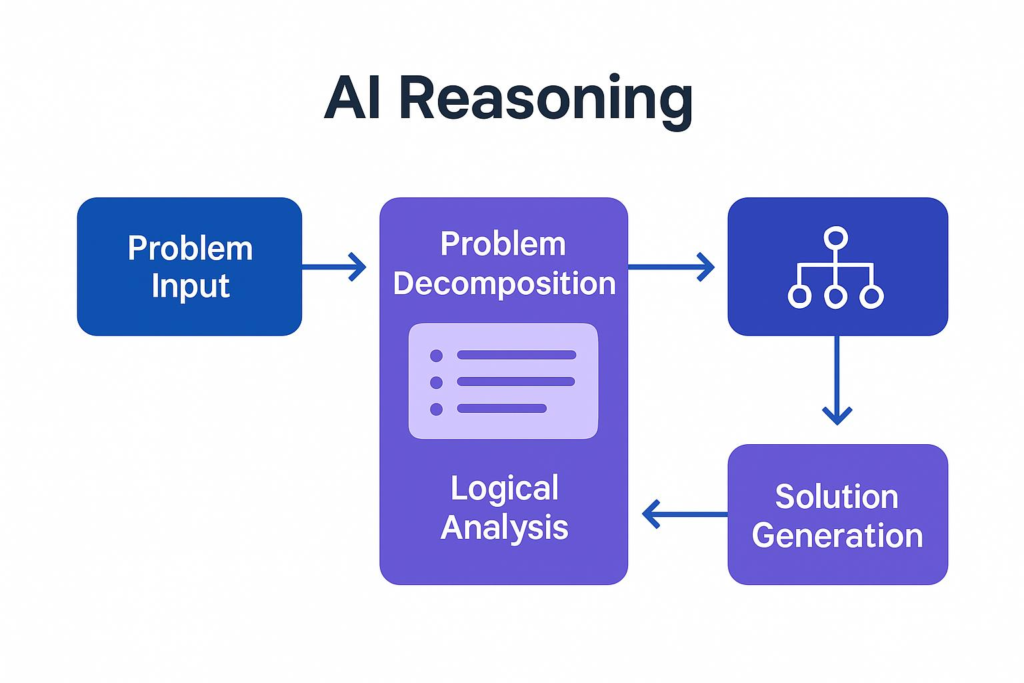
4) Reasoning Architecture: Core Model
The Reasoning Flow
A well-architected reasoning agent follows a systematic process that mirrors human problem-solving:
Claude-Optimized Architecture
When building with Claude 3.5 Sonnet, the architecture should leverage the model’s native strengths:
- Long-context processing enables feeding entire reasoning histories
- Structured outputs (via tool use) ensure parseable responses
- Constitutional safeguards provide built-in safety guardrails
5) Core Design Patterns for Claude-Based Reasoning Agents
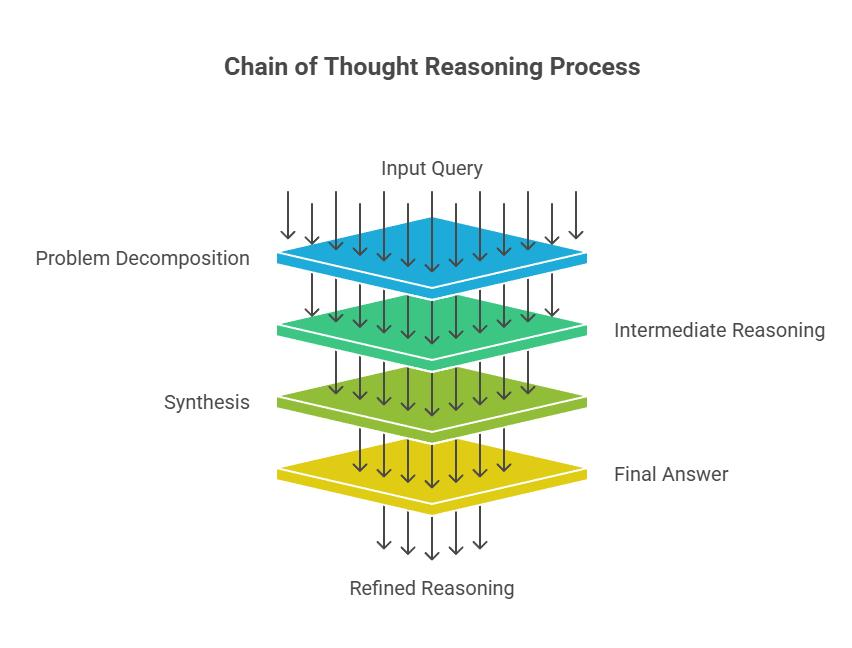
Pattern 1: Chain-of-Thought (CoT) Reasoning
Chain-of-Thought prompting encourages the model to articulate its reasoning process before delivering a final answer. This pattern dramatically improves accuracy on complex tasks by making the reasoning explicit and debuggable.
Implementation:
python
prompt = """ Solve the following problem step by step. Show your reasoning at each stage. Problem: A company's revenue grew from $2.5M to $3.8M in one year. If operating expenses were 40% of revenue at the start and 35% at the end, calculate the percentage change in operating profit. Step 1: Calculate initial and final operating profit Step 2: Calculate absolute change Step 3: Calculate percentage change Step 4: Verify calculations Begin reasoning: """
Use Cases:
- Mathematical problem-solving
- Logical analysis and deduction
- Technical troubleshooting
- Strategic planning
Pattern 2: Self-Reflection Loop
Self-reflection enables agents to critique and improve their own outputs. This pattern creates a virtuous cycle of continuous refinement.
Process Flow:
text
Step 1: Generate initial answer
↓
Step 2: Evaluate correctness (self-critique)
↓
Step 3: Identify gaps or errors
↓
Step 4: Refine and improve response
↓
Step 5: Repeat until validation passes
Implementation Pattern:
python
reflection_prompt = """
You are solving: {problem}
Initial answer: {answer}
Now act as a critic. Evaluate this answer for:
1. Logical correctness
2. Completeness
3. Potential errors
4. Alternative approaches
Provide specific feedback, then generate an improved version.
"""
Pattern 3: Tool-Augmented Reasoning
Claude’s native tool-use capabilities enable agents to combine reasoning with external actions. The agent decides when to invoke tools, processes results, and incorporates them into its reasoning chain.
Tool Definition (Claude Format):
python
tools = [
{
"name": "calculate",
"description": "Perform mathematical calculations",
"input_schema": {
"type": "object",
"properties": {
"expression": {
"type": "string",
"description": "Mathematical expression to evaluate"
}
},
"required": ["expression"]
}
},
{
"name": "search_database",
"description": "Query internal knowledge base",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string"},
"filters": {"type": "object"}
},
"required": ["query"]
}
}
]
Pattern 4: Multi-Step Planning
For complex tasks requiring coordinated actions, the agent first creates a structured plan, then executes step by step, adapting as needed.
Planning Structure:
json
{
"plan": [
{
"step": 1,
"action": "gather_requirements",
"depends_on": [],
"expected_output": "requirements_document"
},
{
"step": 2,
"action": "design_architecture",
"depends_on": [1],
"expected_output": "architecture_diagram"
},
{
"step": 3,
"action": "implement_core_logic",
"depends_on": [2],
"expected_output": "implementation_code"
},
{
"step": 4,
"action": "test_and_validate",
"depends_on": [3],
"expected_output": "test_results"
}
]
}
6) Implementation Blueprint: Complete Python Example
Step 1: Installation and Setup
bash
pip install anthropic pip install pydantic # For structured outputs
Step 2: Basic Client Configuration
python
import anthropic
from typing import List, Dict, Any
import json
class ClaudeReasoningAgent:
def __init__(self, api_key: str, model: str = "claude-3-5-sonnet-20241022"):
self.client = anthropic.Anthropic(api_key=api_key)
self.model = model
self.conversation_history = []
def reason(self, problem: str, steps: List[str] = None) -> Dict[str, Any]:
"""
Execute structured reasoning on a complex problem
"""
# Build reasoning prompt
prompt = self._build_reasoning_prompt(problem, steps)
# Get response with reasoning
response = self.client.messages.create(
model=self.model,
max_tokens=4096,
temperature=0.2, # Lower temperature for precise reasoning
messages=[
{"role": "system", "content": self._system_prompt()},
{"role": "user", "content": prompt}
]
)
return self._parse_response(response)
def _system_prompt(self) -> str:
return """You are an advanced reasoning agent. Follow these principles:
1. Always show your reasoning step by step
2. Validate your conclusions before finalizing
3. Consider alternative approaches
4. If uncertain, acknowledge limitations
5. Use structured formatting for clarity"""
def _build_reasoning_prompt(self, problem: str, steps: List[str] = None) -> str:
if steps:
step_guide = "\n".join([f"{i+1}. {step}" for i, step in enumerate(steps)])
return f"""
Problem: {problem}
Follow this reasoning structure:
{step_guide}
Provide your reasoning in sections:
[UNDERSTANDING]
[DECOMPOSITION]
[REASONING]
[SOLUTION]
[VALIDATION]
"""
else:
return f"""
Problem: {problem}
Break this down systematically:
1. What is the core question?
2. What information do I have?
3. What steps are needed?
4. Execute each step with reasoning
5. Validate the final answer
"""
def _parse_response(self, response) -> Dict[str, Any]:
content = response.content[0].text
# Extract sections (simplified parsing)
sections = {
"full_response": content,
"token_usage": {
"input": response.usage.input_tokens,
"output": response.usage.output_tokens
}
}
# Parse sections if present
for section in ["UNDERSTANDING", "DECOMPOSITION", "REASONING", "SOLUTION", "VALIDATION"]:
if section in content:
start = content.find(f"[{section}]") + len(section) + 2
end = content.find("[", start) if content.find("[", start) > 0 else len(content)
sections[section.lower()] = content[start:end].strip()
return sections
Step 3: Tool-Enabled Reasoning Agent
python
class ToolEnabledReasoningAgent(ClaudeReasoningAgent):
def __init__(self, api_key: str, tools: List[Dict] = None):
super().__init__(api_key)
self.tools = tools or []
def reason_with_tools(self, problem: str) -> Dict[str, Any]:
"""
Reason with ability to invoke tools
"""
response = self.client.messages.create(
model=self.model,
max_tokens=4096,
tools=self.tools,
messages=[
{"role": "system", "content": self._tool_system_prompt()},
{"role": "user", "content": problem}
]
)
# Handle tool calls if present
for content_block in response.content:
if content_block.type == "tool_use":
tool_result = self._execute_tool(
content_block.name,
content_block.input
)
# Continue conversation with tool result
# (Implementation continues...)
return self._parse_response(response)
def _tool_system_prompt(self) -> str:
return """You are a reasoning agent with access to tools.
Use tools when they help solve the problem.
Explain your reasoning for tool use.
Incorporate tool results into your final answer."""
Step 4: Self-Reflective Agent with Validation
python
class SelfReflectiveAgent(ClaudeReasoningAgent):
def reason_with_reflection(self, problem: str, max_iterations: int = 3) -> Dict[str, Any]:
"""
Iteratively refine answers through self-reflection
"""
current_answer = None
for iteration in range(max_iterations):
if iteration == 0:
# Initial reasoning
response = self._generate_initial_reasoning(problem)
current_answer = response["solution"]
else:
# Reflection and refinement
response = self._reflect_and_refine(problem, current_answer)
current_answer = response["refined_solution"]
# Check if answer meets quality threshold
if self._validate_answer(current_answer, problem):
break
return {
"final_answer": current_answer,
"iterations": iteration + 1,
"reasoning_trace": response
}
def _generate_initial_reasoning(self, problem: str) -> Dict:
prompt = f"""
Problem: {problem}
Provide a complete solution with:
- Step-by-step reasoning
- Final answer in [ANSWER] tags
- Confidence level (1-10)
"""
response = self.client.messages.create(
model=self.model,
max_tokens=4096,
messages=[{"role": "user", "content": prompt}]
)
return {"solution": response.content[0].text}
def _reflect_and_refine(self, problem: str, previous_answer: str) -> Dict:
prompt = f"""
Problem: {problem}
Previous answer:
{previous_answer}
Now act as a critical reviewer:
1. What are the strengths of this answer?
2. What are the weaknesses or gaps?
3. How could it be improved?
4. Provide a refined, improved version.
Show your critique and then the refined answer in [REFINED_ANSWER] tags.
"""
response = self.client.messages.create(
model=self.model,
max_tokens=4096,
messages=[{"role": "user", "content": prompt}]
)
return {"refined_solution": response.content[0].text}
def _validate_answer(self, answer: str, problem: str) -> bool:
"""Simple validation - can be expanded with custom logic"""
# Check for basic completeness
if len(answer) < 50:
return False
# Check if answer contains solution markers
if "ANSWER" not in answer and "solution" not in answer.lower():
return False
return True
Step 5: Multi-Agent Reasoning with Claude
python
class MultiAgentReasoningSystem:
"""
Orchestrates multiple specialized reasoning agents
"""
def __init__(self, api_key: str):
self.client = anthropic.Anthropic(api_key=api_key)
self.agents = {
"planner": ClaudeReasoningAgent(api_key),
"executor": ClaudeReasoningAgent(api_key),
"validator": ClaudeReasoningAgent(api_key)
}
def solve_complex_problem(self, problem: str) -> Dict[str, Any]:
"""
Coordinate multiple reasoning agents
"""
# Phase 1: Planning
plan = self._create_plan(problem)
# Phase 2: Execution
execution_results = self._execute_plan(plan)
# Phase 3: Validation
validated = self._validate_and_synthesize(execution_results)
return validated
def _create_plan(self, problem: str) -> Dict:
planner_prompt = f"""
Create a detailed execution plan for:
{problem}
Break into sub-tasks with:
- Task description
- Dependencies
- Expected output format
Return as structured plan.
"""
response = self.client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=2048,
messages=[{"role": "user", "content": planner_prompt}]
)
return self._parse_plan(response.content[0].text)
def _execute_plan(self, plan: Dict) -> List[Dict]:
# Implementation for coordinated execution
results = []
for task in plan.get("tasks", []):
result = self.agents["executor"].reason(task["description"])
results.append({"task": task["name"], "result": result})
return results
def _validate_and_synthesize(self, results: List[Dict]) -> Dict:
validator_prompt = f"""
Review these execution results:
{json.dumps(results, indent=2)}
Validate:
1. Consistency across tasks
2. Completeness
3. Accuracy
Synthesize into a final, coherent answer.
"""
response = self.client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=2048,
messages=[{"role": "user", "content": validator_prompt}]
)
return {
"final_answer": response.content[0].text,
"execution_trace": results
}
7) Comparative Analysis: Claude 3.5 Sonnet vs. Other Models
| Feature | Claude 3.5 Sonnet | GPT-4o | Gemini 1.5 Pro |
|---|---|---|---|
| Reasoning Depth | Very High | High | Medium-High |
| Context Length | 200K tokens | 128K tokens | 2M tokens |
| Chain-of-Thought | Native optimization | Requires prompting | Good |
| Code Generation | Advanced | Advanced | Moderate |
| Tool Use | Native function calling | Native | Native |
| Safety & Alignment | Constitutional AI | Moderation APIs | Safety filters |
| Price per 1M tokens (input) | $3.00 | $2.50 | $3.50 |
| Price per 1M tokens (output) | $15.00 | $10.00 | $10.50 |
| Best Use Case | Complex reasoning agents | General applications | Multi-modal, long documents |
When to Choose Claude 3.5 Sonnet
- Reasoning-intensive applications: Code analysis, mathematical problem-solving, strategic planning
- Long-context reasoning: Analyzing entire codebases or extensive documentation
- Safety-critical systems: Regulated industries requiring controlled outputs
- Tool-augmented agents: Complex workflows requiring orchestrated tool use
8) Real-World Applications
8.1 Software Engineering Agents
Capability: Autonomous code generation, debugging, and architecture design
python
class SoftwareEngineeringAgent:
def analyze_codebase(self, code: str) -> Dict:
"""
Analyze entire codebase for bugs, improvements
"""
prompt = f"""
Analyze this codebase for:
1. Potential bugs or edge cases
2. Performance optimizations
3. Security vulnerabilities
4. Code style improvements
Code:
{code}
Provide detailed analysis with line references and fix suggestions.
"""
# Claude processes up to 200K tokens - entire codebase
return self.claude.reason(prompt)
def generate_architecture(self, requirements: str) -> str:
"""
Design system architecture from requirements
"""
# Multi-step reasoning for architecture design
pass
8.2 Research & Analysis Systems
Use Case: Literature review, data synthesis, insight generation
text
Research Input: 50+ research papers (PDFs converted to text) Claude Processing: 200K context window enables full paper analysis Output: Synthesized findings, identified gaps, research recommendations
8.3 Financial Decision Systems
Capabilities:
- Risk analysis across portfolios
- Market trend forecasting
- Investment strategy planning
- Regulatory compliance checking
Example: A financial agent analyzes quarterly reports, market data, and economic indicators to recommend portfolio adjustments with documented reasoning.
8.4 Healthcare Decision Support (Non-Diagnostic)
Use Cases:
- Clinical literature synthesis
- Treatment pathway analysis
- Patient data summarization
- Research hypothesis generation
Note: Claude is not FDA-approved for diagnostic use; supports research and administrative functions
9) Advanced Architecture: Enterprise Reasoning Systems
Component Architecture
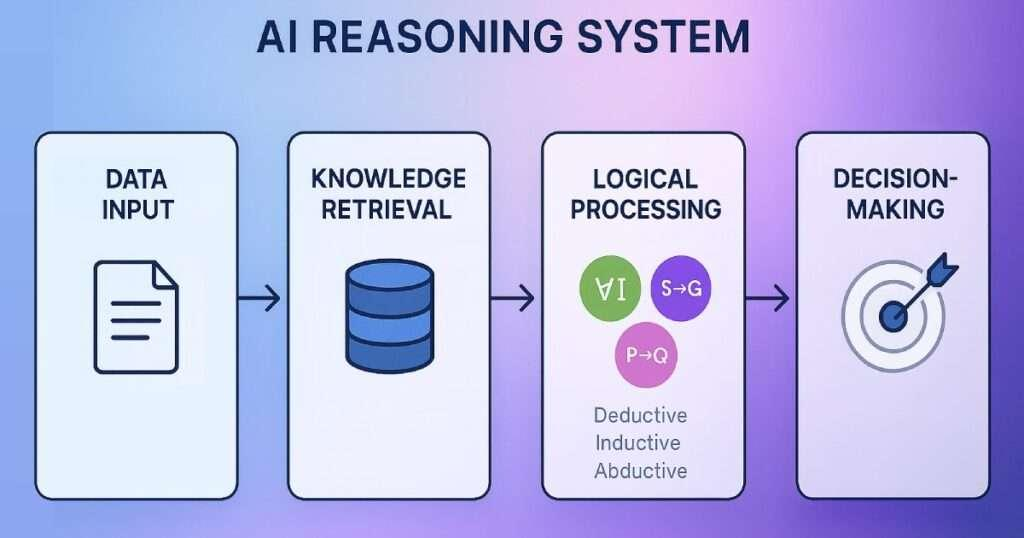
Orchestration with Semantic Kernel
python
from semantic_kernel import Kernel
from semantic_kernel.connectors.ai.anthropic import AnthropicChatCompletion
# Initialize Semantic Kernel with Claude
kernel = Kernel()
kernel.add_service(AnthropicChatCompletion(
model="claude-3-5-sonnet",
api_key=api_key
))
# Create reasoning plugin
class ReasoningPlugin:
@kernel_function(description="Solve complex problems with step-by-step reasoning")
def solve(self, problem: str) -> str:
# Implement structured reasoning with Claude
pass
# Add to kernel and orchestrate
kernel.add_plugin(ReasoningPlugin())
10) Common Challenges and Solutions
| Challenge | Cause | Solution |
|---|---|---|
| Hallucination | Insufficient context or weak prompts | Add structured reasoning, enforce validation loops, provide explicit constraints |
| Overthinking | Too many reasoning steps without stopping criteria | Limit maximum reasoning depth, implement confidence thresholds |
| Cost | Long responses with high token usage | Optimize prompts, cache common patterns, use response streaming |
| Latency | Heavy processing chains | Parallelize independent sub-tasks, implement caching, use smaller models for simple tasks |
| Inconsistent Output Format | Lack of structured output guidance | Use tool definitions for structured outputs, enforce JSON schemas |
| Tool Use Errors | Model misinterprets tool purpose | Provide detailed tool descriptions with examples, validate inputs before execution |
11) Best Practices for Claude-Based Reasoning Agents
1. Prompt Design
- Use clear section markers (
[REASONING],[ANSWER]) - Include examples of desired reasoning patterns
- Set appropriate temperature (0.1–0.3 for deterministic reasoning, 0.7+ for creative)
2. Reasoning Structure
- Always require step-by-step explanation
- Implement self-consistency checks
- Encourage consideration of alternatives
3. Tool Integration
- Define tools with explicit schemas
- Validate tool inputs before execution
- Handle tool errors gracefully
4. Memory Management
- Use vector databases for long-term memory
- Summarize conversation history to manage context
- Implement semantic search for relevant past interactions
5. Cost Optimization
- Cache frequent queries
- Use smaller models for routine tasks
- Monitor token usage per session
6. Safety and Alignment
- Implement output filtering
- Use Claude’s constitutional AI safeguards
- Add human-in-the-loop for critical decisions
12) MHTECHIN Strategy for Reasoning Agents
Our Approach
At MHTECHIN, we build enterprise-grade reasoning systems by combining Claude 3.5 Sonnet with modern orchestration frameworks and data architectures.
Technology Stack Integration
| Layer | Technology | Purpose |
|---|---|---|
| Reasoning | Claude 3.5 Sonnet | Core reasoning engine |
| Data Indexing | LlamaIndex | Document processing and retrieval |
| Workflow | LangGraph | Complex agent workflows |
| Collaboration | CrewAI / AutoGen | Multi-agent coordination |
| Orchestration | Semantic Kernel | Enterprise integration |
| Vector Storage | Qdrant / Pinecone | Memory and retrieval |
| Observability | LangSmith / Weights & Biases | Monitoring and debugging |
Development Methodology
text
Phase 1: Problem Definition
↓
Phase 2: Reasoning Workflow Design
↓
Phase 3: Tool and Memory Integration
↓
Phase 4: Validation Loop Implementation
↓
Phase 5: Scalable Deployment
↓
Phase 6: Continuous Optimization
MHTECHIN Differentiators
- Deep Claude expertise: Specialized knowledge of Anthropic’s API and best practices
- Enterprise integration: Seamless connection to existing systems and data sources
- Production focus: Observability, security, and scalability from day one
- Hybrid architectures: Combining Claude with other models and frameworks as needed
[Partner with MHTECHIN to build intelligent reasoning agents that transform your business operations. Contact us to discuss your specific use case.]
13) Future of Reasoning Agents
The trajectory of AI agents points toward increasingly autonomous and capable systems:
Emerging Trends
- Autonomous Decision-Making: Agents that make independent decisions within defined boundaries
- Self-Improving Systems: Agents that learn from their own performance and improve over time
- Multi-Agent Reasoning Teams: Specialized agents collaborating on complex problems
- Human-AI Collaboration: Seamless integration of human oversight into agent workflows
- Long-Term Memory: Persistent memory across sessions for continuous learning
The Role of Claude-Like Models
Models optimized for reasoning—like Claude 3.5 Sonnet—will form the cognitive core of these systems. They provide the structured thinking, tool use, and safety alignment necessary for autonomous operation.
14) Conclusion
Claude 3.5 Sonnet represents a significant advancement in AI reasoning capabilities, enabling developers to build agents that don’t just respond—they think.
Key takeaways:
- Structured reasoning dramatically improves accuracy on complex tasks
- Chain-of-Thought and self-reflection patterns enable traceable, verifiable outputs
- Tool integration extends reasoning into actionable workflows
- Enterprise architectures combine Claude with orchestration frameworks for production-ready systems
When combined with modern frameworks like Semantic Kernel, LlamaIndex, and LangGraph, Claude becomes the foundation for next-generation AI systems that can:
- Analyze complex problems step by step
- Execute multi-step plans with tool integration
- Validate and improve their own outputs
- Collaborate with human users and other agents
MHTECHIN brings the expertise to navigate this complex landscape, helping organizations leverage Claude 3.5 Sonnet and complementary technologies to build intelligent, scalable, and high-performing AI solutions that deliver measurable business value.
[Ready to build reasoning agents with Claude 3.5 Sonnet? Contact MHTECHIN to start your journey toward intelligent, autonomous AI systems.]
15) FAQ (SEO Optimized)
Q1: What is Claude 3.5 Sonnet?
A: Claude 3.5 Sonnet is an advanced AI model developed by Anthropic, optimized for complex reasoning, multi-step problem-solving, and structured thinking. It features a 200K token context window and native tool-use capabilities, making it ideal for building sophisticated AI agents.
Q2: Why should I use Claude for building AI agents?
A: Claude 3.5 Sonnet excels at reasoning-heavy tasks due to its training methodology (constitutional AI) and architectural optimizations. It provides step-by-step reasoning, long-context understanding (entire codebases), native tool integration, and strong safety alignment—critical capabilities for production agent systems.
Q3: Can Claude build autonomous agents?
A: Yes. When combined with orchestration frameworks like Semantic Kernel or LangGraph, Claude can serve as the reasoning core for autonomous agents. The model supports tool use, memory integration, and self-reflection patterns necessary for autonomous operation.
Q4: Is Claude better than GPT for reasoning tasks?
A: For reasoning-intensive applications—code analysis, mathematical problem-solving, strategic planning—Claude 3.5 Sonnet is highly competitive and often preferred due to its structured reasoning approach and longer context window. The choice depends on specific use cases, integration requirements, and cost considerations.
Q5: What are reasoning agents?
A: Reasoning agents are AI systems that solve problems through explicit, step-by-step logical processes. Unlike basic chatbots that provide direct responses, reasoning agents decompose problems, evaluate multiple approaches, validate outputs, and iteratively refine solutions.
Q6: How do I implement Chain-of-Thought with Claude?
A: Use prompts that explicitly ask Claude to show reasoning step by step. Structure prompts with sections like [UNDERSTANDING], [DECOMPOSITION], [REASONING], and [VALIDATION]. Set temperature low (0.2) for deterministic reasoning chains.
Q7: What frameworks work best with Claude for agent development?
A: Popular choices include Semantic Kernel (for Microsoft ecosystem integration), LangGraph (for complex workflows), CrewAI (for multi-agent collaboration), and LlamaIndex (for RAG and document processing). MHTECHIN specializes in combining these with Claude for enterprise solutions.
Q8: How does Claude handle long contexts?
A: Claude 3.5 Sonnet supports up to 200,000 tokens per request—sufficient to process entire codebases, lengthy research papers, or extensive conversation histories. This enables agents to reason over complete information without fragmentation.
Q9: What are the costs of using Claude for reasoning agents?
A: Pricing as of 2026: $3.00 per million input tokens, $15.00 per million output tokens. Costs can be optimized through caching, prompt optimization, and using smaller models for routine tasks. MHTECHIN helps clients implement cost-effective architectures.
Q10: How can MHTECHIN help with Claude-based agents?
A: MHTECHIN provides end-to-end services including strategy definition, architecture design, implementation, integration with existing systems, and ongoing optimization. Our team has deep expertise in Claude, Semantic Kernel, and enterprise AI architectures.
Leave a Reply