Introduction
Behind every successful AI system is a well-prepared dataset. Whether it is a chatbot that answers customer questions accurately, a computer vision system that detects defects reliably, or a predictive model that forecasts demand precisely—the quality of the training data determines the quality of the AI.
Yet data preparation is often the most underestimated part of AI development. Teams rush to train models without properly cleaning, labeling, or validating their data. The result? Models that are inaccurate, biased, or prone to hallucinations. In fact, data scientists spend 60–80% of their time on data preparation—not because they enjoy it, but because it is essential.
This article explains what AI training data is, why it matters, and how to prepare datasets for accurate, reliable models. Whether you are a business leader planning an AI project, a professional working with data teams, or someone building foundational AI literacy, this guide will help you understand the foundation of every AI system.
For a foundational understanding of AI hallucinations and why they happen, you may find our guide on AI Hallucinations: Why AI Makes Up Facts and How to Prevent It helpful as a starting point.
Throughout, we will highlight how MHTECHIN helps organizations prepare high-quality datasets and build AI systems that deliver accurate, trustworthy results.
Section 1: What Is AI Training Data?
1.1 A Simple Definition
AI training data is the collection of examples used to teach an AI model how to perform its task. The model learns patterns, relationships, and rules from these examples. The quality, quantity, and diversity of the training data directly determine how well the model will perform on new, unseen data.
Think of training data as the textbook for an AI. If the textbook is accurate, comprehensive, and well-organized, the AI will learn correctly. If the textbook contains errors, gaps, or biases, the AI will learn those too.
1.2 Types of AI Training Data
| Type | Description | Example |
|---|---|---|
| Structured Data | Organized in rows and columns, like spreadsheets | Customer records with columns for age, income, purchase history |
| Unstructured Data | No predefined format; requires processing | Text documents, images, audio files, video |
| Labeled Data | Examples with correct answers provided | Images marked “cat” or “not cat” |
| Unlabeled Data | Raw data without answers | Millions of unlabeled customer support transcripts |
| Synthetic Data | Artificially generated data | Computer-generated images of products in various settings |
1.3 How Training Data Is Used
Different AI tasks require different types of training data:
- Supervised learning. Requires labeled data—examples with the correct answers. A spam filter needs emails labeled “spam” or “not spam.”
- Unsupervised learning. Uses unlabeled data to find patterns. Customer segmentation models group customers without pre-existing labels.
- Reinforcement learning. Uses reward signals rather than labeled examples. The model learns through trial and error.
- Generative AI. Requires massive amounts of unstructured content—text, images, audio—to learn patterns for creation.
1.4 The Data-Accuracy Connection
The relationship between training data and model accuracy is direct:
- More data generally improves accuracy (to a point)
- Higher-quality data improves accuracy significantly
- Diverse data ensures the model generalizes to real-world conditions
- Biased data produces biased models
- Noisy data (errors, inconsistencies) produces inaccurate models
A model trained on garbage data will produce garbage results. There is no way around it.
Section 2: The Data Preparation Process
2.1 Overview: From Raw Data to Ready-to-Train
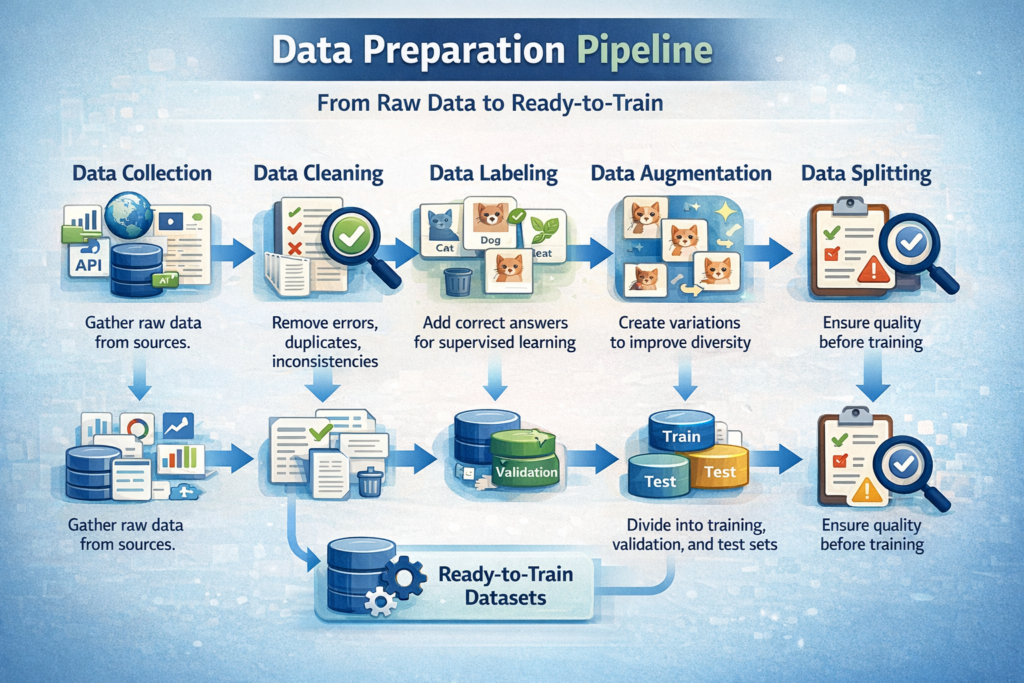
Data preparation transforms raw, messy data into a clean, structured format suitable for training. The process typically includes:
- Data collection. Gathering raw data from sources
- Data cleaning. Removing errors, duplicates, inconsistencies
- Data labeling. Adding correct answers for supervised learning
- Data augmentation. Creating variations to improve diversity
- Data splitting. Dividing into training, validation, and test sets
- Data validation. Ensuring quality before training
Each step is critical. Skipping or rushing any step compromises the final model.
2.2 Data Collection: Where Data Comes From
| Source | Examples | Considerations |
|---|---|---|
| Internal systems | CRM, ERP, transaction logs, customer support tickets | Often readily available but may have quality issues |
| Public datasets | Government data, academic datasets, open-source repositories | Free but may not match your specific use case |
| Third-party providers | Data vendors, industry benchmarks | Can fill gaps but may have licensing restrictions |
| User-generated data | Customer feedback, reviews, social media | Valuable but messy and requires careful handling |
| Synthetic data | Artificially generated examples | Useful when real data is scarce or sensitive |
| Web scraping | Publicly available websites | Requires attention to terms of service and legality |
2.3 Data Cleaning: Removing the Noise
Data cleaning is often the most time-consuming step. Common issues to address:
| Issue | Example | Fix |
|---|---|---|
| Missing values | Customer age field blank | Impute (fill with average) or remove rows |
| Duplicates | Same transaction recorded twice | Deduplicate based on unique identifiers |
| Inconsistent formatting | “NY”, “New York”, “new york” | Standardize to a single format |
| Outliers | Age = 999 | Detect and handle (investigate, cap, or remove) |
| Errors | “January 32, 2024” | Validate date ranges; correct or remove |
| Irrelevant data | Columns that do not relate to the target | Remove |
2.4 Data Labeling: Adding Correct Answers
For supervised learning, labeled data is essential. Labeling is the process of adding the correct answer to each example.
| Labeling Approach | How It Works | Best For |
|---|---|---|
| In-house experts | Domain experts label data internally | Small, high-stakes datasets requiring expertise |
| Crowdsourcing | Large number of people label via platforms | Large-scale, lower-stakes labeling |
| Active learning | Model identifies uncertain examples; humans label those | Efficient labeling with limited resources |
| Synthetic labeling | Rules or heuristics generate labels automatically | When clear rules exist; requires validation |
| Outsourcing | Specialized vendors provide labeling services | Large-scale projects with quality requirements |
Labeling quality is critical. Inconsistent or incorrect labels directly cause model errors. For medical imaging, hiring radiologists to label is expensive but necessary. For product categorization, trained annotators with clear guidelines are essential.
Section 3: Key Principles for High-Quality Training Data
3.1 Principle 1: Quality Over Quantity
More data is not always better. A smaller, high-quality dataset often outperforms a larger, noisy dataset. A model trained on 10,000 clean, accurately labeled examples will generally perform better than a model trained on 100,000 examples with 20% labeling errors.
Focus on: Accuracy of labels, consistency across annotators, handling of edge cases.
3.2 Principle 2: Diversity Matters
A model is only as good as its training data. If your dataset lacks diversity, the model will fail on underrepresented examples.
- Image recognition. If training data contains only daytime images, the model will fail at night.
- Speech recognition. If training data contains only one accent, the model will struggle with others.
- Customer service. If training data contains only formal language, the model will miss casual inquiries.
Diversity dimensions: Demographics, geography, lighting, angles, language styles, device types, time periods.
3.3 Principle 3: Represent Real-World Conditions
Training data must reflect the conditions where the model will be deployed. A model trained on pristine, clean data will fail when real-world data is messy.
- Computer vision. Train on images with varying lighting, backgrounds, angles, and occlusions.
- NLP. Train on actual customer messages with typos, slang, and incomplete sentences.
- Predictive models. Train on data that includes rare events (fraud, churn) at realistic frequencies.
3.4 Principle 4: Address Bias Proactively
Biased training data produces biased models. Common bias sources:
| Bias Type | Example | Mitigation |
|---|---|---|
| Selection bias | Training data only from one region | Ensure geographic diversity |
| Labeling bias | Annotators’ subjective judgments | Multiple annotators, clear guidelines |
| Historical bias | Data reflects past discrimination | Audit for disparate impact |
| Measurement bias | Data collection methods differ | Standardize collection processes |
Proactive steps: Audit datasets for representation gaps, test models on diverse subsets, involve domain experts in bias assessment.
3.5 Principle 5: Validate Before Training
Always validate your dataset before investing time in training. Simple validation steps:
- Statistical checks. Distributions of key variables—do they match expectations?
- Random sampling. Manually review a random sample of examples to assess labeling quality.
- Edge case review. Examine examples near decision boundaries—are they correctly labeled?
- Holdout testing. Set aside a test set from the start; evaluate after training.
Section 4: Preparing Data for Different AI Types
4.1 Data for Predictive AI (Classification, Regression, Forecasting)
Predictive AI requires structured data with known outcomes. Key steps:
| Step | Description |
|---|---|
| Define the target variable | What are you predicting? (e.g., churn yes/no, sales amount) |
| Collect historical data | Gather data with known outcomes over time |
| Feature engineering | Create meaningful input variables from raw data |
| Handle missing values | Decide whether to impute or remove |
| Normalize/scale | Ensure numerical features are on comparable scales |
| Split chronologically | For time-series, train on past, test on future |
Common pitfalls: Using future data in training (data leakage), insufficient historical data for rare events, inconsistent definitions over time.
4.2 Data for Generative AI (LLMs, Image Generators)
Generative AI requires massive amounts of unstructured content. Key considerations:
| Consideration | Description |
|---|---|
| Scale | LLMs require trillions of words; image generators require millions of images |
| Diversity | Content must cover the range of topics, styles, and domains you need |
| Quality filtering | Remove harmful, low-quality, or irrelevant content |
| Deduplication | Remove duplicate content to avoid overfitting |
| Licensing | Ensure you have rights to use the data for training |
| Privacy | Remove personally identifiable information (PII) |
For fine-tuning: Smaller, high-quality datasets of thousands or tens of thousands of examples can adapt general models to specific domains.
4.3 Data for Computer Vision
Computer vision requires images or video with annotations. Key steps:
| Step | Description |
|---|---|
| Image collection | Gather images covering all relevant scenarios |
| Annotation type | Classification labels, bounding boxes, segmentation masks |
| Annotation quality | Multiple annotators, consensus checks |
| Data augmentation | Rotations, crops, color shifts to increase diversity |
| Balancing | Ensure each class has sufficient examples |
| Lighting and angle diversity | Include varied conditions |
Common pitfalls: Overfitting to training lighting/angles, insufficient examples for rare objects, inconsistent annotation boundaries.
4.4 Data for NLP (Text Models)
NLP models require text data with appropriate annotations. Key considerations:
| Consideration | Description |
|---|---|
| Text cleaning | Handle encoding issues, standardize formatting |
| Language detection | Ensure data matches target language |
| Privacy filtering | Remove PII, sensitive information |
| Labeling | Intent classification, entity extraction, sentiment |
| Class balance | Ensure all intent classes have sufficient examples |
| Edge cases | Include ambiguous, complex examples |
Section 5: Common Data Pitfalls and How to Avoid Them
5.1 Data Leakage
What it is: Information from the future or the test set inadvertently used in training.
Examples:
- Using customer satisfaction scores from after churn to predict churn
- Including the test set in training
- Using features that would not be available at prediction time
Prevention: Careful feature selection, strict chronological splitting, separate validation from training.
5.2 Insufficient Data for Rare Events
What it is: Rare events (fraud, equipment failure) are underrepresented, so the model never learns to detect them.
Prevention:
- Collect more historical data to capture rare events
- Use synthetic data to augment rare examples
- Use techniques like oversampling or class weighting
- Consider anomaly detection approaches
5.3 Labeling Inconsistency
What it is: Different annotators label the same type of example differently.
Prevention:
- Provide clear annotation guidelines with examples
- Use multiple annotators per example; measure agreement
- Conduct regular quality reviews
- Use consensus or adjudication for disagreements
5.4 Concept Drift
What it is: The relationship between inputs and outputs changes over time. A model trained on old data becomes inaccurate.
Prevention:
- Monitor model performance over time
- Regularly retrain on recent data
- Design for continuous learning and updates
5.5 Privacy and Compliance Violations
What it is: Training data contains sensitive information that should not be used or exposed.
Prevention:
- Anonymize or remove PII
- Understand data residency requirements
- Implement access controls
- Document data lineage and usage rights
Section 6: How MHTECHIN Helps with AI Training Data
Data preparation is one of the most critical—and most underestimated—parts of AI development. MHTECHIN helps organizations build high-quality datasets that lead to accurate, reliable models.
6.1 For Data Strategy and Planning
MHTECHIN helps organizations:
- Assess data readiness. What data do you have? What gaps exist?
- Define labeling requirements. What annotations are needed? What quality standards?
- Estimate data needs. How many examples are required for your use case?
- Plan for privacy and compliance. What regulations apply? How to protect sensitive data?
6.2 For Data Preparation and Labeling
MHTECHIN provides hands-on support:
- Data collection. Identify and acquire relevant data sources
- Data cleaning. Remove errors, inconsistencies, and duplicates
- Data labeling. Design labeling guidelines, manage annotators, ensure quality
- Data augmentation. Create synthetic variations to improve diversity
- Data validation. Audit datasets for quality, bias, and representativeness
6.3 For Ongoing Data Management
MHTECHIN helps organizations maintain data quality over time:
- Monitoring. Track data drift and model performance
- Retraining pipelines. Automate updates with fresh data
- Governance. Establish policies for data access, privacy, and compliance
6.4 The MHTECHIN Approach
MHTECHIN’s data practice is grounded in the principle that quality data is the foundation of quality AI. The team:
- Understands your domain. What data matters? What are the edge cases?
- Applies rigorous processes. Structured workflows for cleaning, labeling, validation.
- Ensures quality. Multiple reviews, consensus checks, statistical validation.
- Builds for the long term. Data pipelines that support continuous improvement.
For organizations building AI, MHTECHIN provides the expertise to get the data right—so the models built on it deliver accurate, trustworthy results.
Section 7: Frequently Asked Questions About AI Training Data
7.1 Q: How much data do I need to train an AI model?
A: It depends on the task, model complexity, and required accuracy. Simple classification with traditional ML may need thousands of examples. Deep learning for images may need hundreds of thousands. Large language models require trillions of words—but you can use pre-trained models and fine-tune with thousands of examples. MHTECHIN can help estimate data needs for your specific use case.
7.2 Q: What is the difference between training data, validation data, and test data?
A: Training data is used to teach the model. Validation data is used during training to tune parameters and prevent overfitting. Test data is held back until the end to evaluate final performance. These sets should be separate and not overlap.
7.3 Q: Can I use pre-trained models instead of training from scratch?
A: Yes. For most business applications, using a pre-trained model (like ChatGPT, ResNet for images) and fine-tuning it on your specific data is more efficient than training from scratch. You still need high-quality data for fine-tuning.
7.4 Q: How do I know if my training data is high quality?
A: Assess labeling accuracy (sampling and reviewing), completeness (are there gaps?), diversity (does it represent real-world conditions?), and consistency (are labels consistent across annotators?). Statistical checks and manual reviews are essential.
7.5 Q: What is data augmentation?
A: Data augmentation is creating variations of existing data to increase diversity without collecting new examples. For images: rotations, crops, color shifts. For text: paraphrasing, word replacement. This helps models generalize better.
7.6 Q: How do I handle sensitive data in training?
A: Anonymize or remove personally identifiable information (PII). Use data residency controls to keep data in required regions. Implement access controls. Consider synthetic data as an alternative. Ensure compliance with regulations like HIPAA, GDPR.
7.7 Q: What is data leakage and why is it a problem?
A: Data leakage occurs when information from outside the training set (like future data or test data) is used in training. This makes models appear artificially accurate but fail in real-world deployment. Prevention requires careful feature selection and chronological splitting.
7.8 Q: How do I label data for supervised learning?
A: Options include in-house experts (best for specialized domains), crowdsourcing (for large-scale, lower-stakes labeling), and outsourcing to specialized vendors. Critical factors: clear guidelines, multiple annotators, quality review.
7.9 Q: What if I do not have enough labeled data?
A: Consider using pre-trained models with fine-tuning (requires less labeled data). Use active learning (model identifies uncertain examples to label). Explore synthetic data generation. Start with a pilot focused on a narrow use case.
7.10 Q: How does MHTECHIN help with training data?
A: MHTECHIN provides end-to-end support: data strategy, collection, cleaning, labeling, augmentation, validation, and ongoing management. Our focus is on building high-quality datasets that lead to accurate, reliable AI models.
Section 8: Conclusion—Data Is the Foundation of AI
AI models are often celebrated for their capabilities—chatbots that converse fluently, vision systems that detect anomalies, predictive models that forecast demand. But behind every successful AI system is a foundation of high-quality training data.
The models do not create intelligence from nothing. They learn patterns from the examples they are given. If those examples are inaccurate, biased, or unrepresentative, the model will be too. If the examples are clean, diverse, and well-labeled, the model can be accurate and reliable.
Data preparation is not glamorous. It requires patience, rigor, and attention to detail. But it is the most important investment you can make in AI development. Cutting corners on data leads to models that fail in production. Investing in data leads to models that deliver real business value.
For organizations building AI, the path is clear: start with data. Understand what you have, what you need, and what it takes to prepare it. Invest in quality. And work with partners who understand that data is not a commodity—it is the foundation of everything that follows.
Ready to build AI on a foundation of quality data? Explore MHTECHIN’s data preparation and AI development services at www.mhtechin.com. From strategy through deployment, our team helps you get the data right—so your models deliver.
This guide is brought to you by MHTECHIN—helping organizations build AI systems on a foundation of quality data. For personalized guidance on data preparation or AI implementation, reach out to the MHTECHIN team today.
Leave a Reply