Introduction
Building an AI system is not a one-step process. It is not just about training a model and putting it into production. Successful AI requires a disciplined journey—from understanding the problem, to gathering and preparing data, to building and validating models, to deploying and monitoring them in the real world. This journey is called the AI lifecycle.
Organizations that treat AI as a single event—train once, deploy forever—almost always fail. Models degrade. Data changes. Requirements evolve. Without a structured lifecycle, AI becomes a source of technical debt, operational risk, and missed opportunity.
This article walks through the complete AI lifecycle, from initial concept to ongoing maintenance. Whether you are a business leader planning an AI initiative, a data scientist building models, or an engineer deploying systems, this guide will help you understand the full journey and the critical steps along the way.
For a foundational understanding of how to govern AI systems responsibly throughout their lifecycle, you may find our guide on AI Governance Frameworks for Enterprises helpful as a starting point.
Throughout, we will highlight how MHTECHIN helps organizations navigate each stage of the AI lifecycle—from strategy through deployment and beyond.
Section 1: Overview of the AI Lifecycle
1.1 What Is the AI Lifecycle?
The AI lifecycle is the end-to-end process of developing, deploying, and maintaining AI systems. It encompasses everything from identifying the business problem to monitoring models in production years later.
Unlike traditional software, AI systems require ongoing attention. Models must be retrained as data changes. Performance must be monitored continuously. And lessons from production must feed back into development.
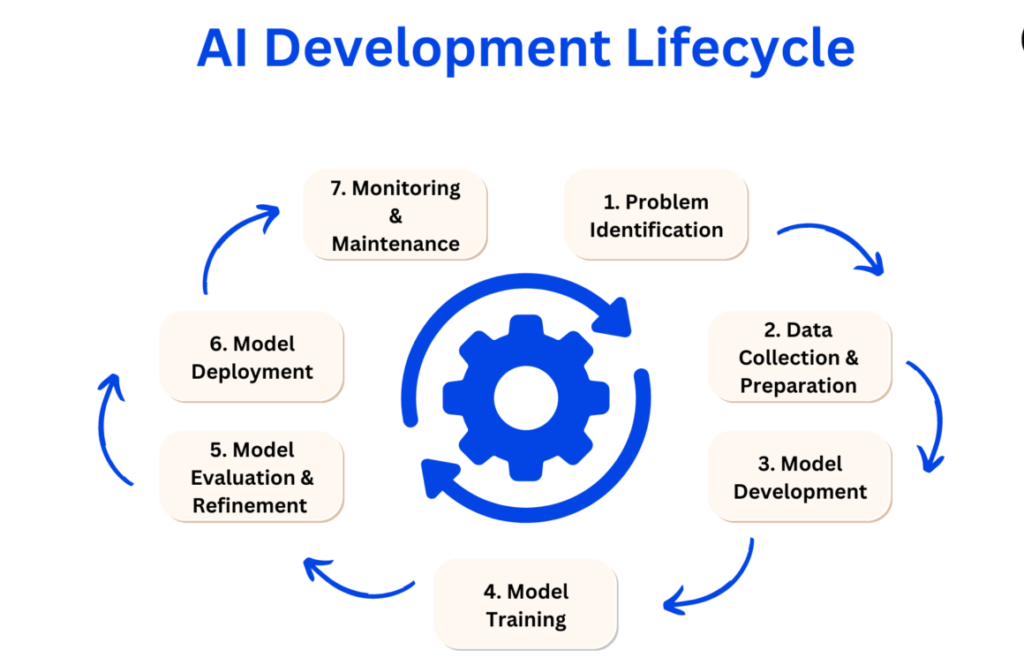
1.2 The Six Stages of the AI Lifecycle
The AI lifecycle can be divided into six interconnected stages:
| Stage | What Happens | Key Activities |
|---|---|---|
| 1. Problem Definition | Clarify the business problem and determine if AI is the right solution | Define objectives, success metrics, feasibility assessment |
| 2. Data Collection | Gather the data needed to train the model | Identify sources, acquire data, assess quality |
| 3. Data Preparation | Clean, label, and transform data for training | Cleaning, labeling, augmentation, splitting |
| 4. Model Development | Build, train, and validate the model | Algorithm selection, training, tuning, validation |
| 5. Deployment | Move the model into production | Integration, scaling, monitoring setup, rollout |
| 6. Monitoring and Maintenance | Ensure the model performs over time | Performance tracking, drift detection, retraining, retirement |
Each stage is critical. Skipping or rushing any stage compromises the final system.
1.3 The Iterative Nature
The AI lifecycle is not linear. Lessons from deployment feed back into development. Monitoring may reveal data quality issues that require revisiting data preparation. Model performance may degrade, triggering retraining. Successful AI organizations embrace iteration.
Section 2: Stage 1—Problem Definition
2.1 Start with the Business Problem, Not the Technology
The most common mistake in AI projects is starting with technology rather than problem. Teams decide to “use AI” without clarifying what problem they are solving. This leads to solutions in search of problems—and eventual failure.
Before any data is collected, ask:
- What business problem are we solving? Be specific. Not “improve customer experience” but “reduce customer service response time by 30%.”
- Is AI the right solution? Some problems are better solved with rule-based systems, simpler analytics, or process changes. AI is not always the answer.
- What does success look like? Define measurable outcomes. Accuracy is not the only metric—consider business impact, cost, and risk.
- What are the constraints? Budget, timeline, regulatory requirements, available talent.
2.2 Feasibility Assessment
Not every AI idea is feasible. Assess:
- Data availability. Do we have the data needed? If not, can we acquire it?
- Data quality. Is the data accurate, complete, and representative?
- Technical feasibility. Is the problem solvable with current techniques?
- Organizational readiness. Do we have the skills, infrastructure, and budget?
A feasibility assessment early saves significant investment in projects that are unlikely to succeed.
2.3 Define Success Metrics
Success metrics should align with business goals, not just technical performance. For a fraud detection system:
- Technical metrics: precision, recall, AUC
- Business metrics: fraud losses avoided, false positive rate, operational cost savings
Both matter. A model with perfect technical metrics may be useless if it creates too many false positives that overwhelm human reviewers.
Section 3: Stage 2—Data Collection
3.1 Identifying Data Sources
Data is the foundation of AI. Without quality data, no model can succeed. Common data sources include:
- Internal systems. CRM, ERP, transaction logs, customer support tickets, sensor data
- Public datasets. Government data, academic datasets, open data repositories
- Third-party providers. Data vendors, industry benchmarks
- User-generated data. Customer feedback, reviews, social media
- Synthetic data. Artificially generated examples for augmentation
3.2 Data Quantity and Quality
How much data is enough? It depends:
- Simple models may need thousands of examples
- Deep learning may need hundreds of thousands or millions
- Pre-trained models with fine-tuning may need less
Quality matters more than quantity. Ten thousand clean, accurately labeled examples often outperform one hundred thousand noisy examples.
3.3 Data Rights and Compliance
Before collecting data, ensure you have the right to use it. Consider:
- Privacy regulations. GDPR, CCPA, HIPAA—what restrictions apply?
- Consent. Was data collected with appropriate consent?
- Licensing. For third-party data, what are the usage restrictions?
- Data residency. Where must data be stored?
Collecting data without proper rights creates legal and regulatory risk.
Section 4: Stage 3—Data Preparation
4.1 Data Cleaning
Raw data is almost never ready for training. Data cleaning addresses:
- Missing values. Decide whether to impute (fill in) or remove
- Duplicates. Remove redundant records
- Inconsistent formatting. Standardize dates, categories, units
- Outliers. Detect and handle extreme values
- Errors. Correct or remove clearly wrong entries
Data cleaning is often the most time-consuming stage—often 60–80% of project time.
4.2 Data Labeling
For supervised learning, labeled data is essential. Labeling options:
- In-house experts. Best for specialized domains where accuracy is critical
- Crowdsourcing. Scalable for large, lower-stakes datasets
- Outsourcing. Specialized vendors for quality labeling at scale
- Active learning. Model identifies uncertain examples; humans label those
Labeling quality is critical. Inconsistent labels lead to poor models.
4.3 Data Augmentation
When data is limited, augmentation creates variations:
- Images. Rotations, crops, color shifts, flips
- Text. Paraphrasing, word replacement, back-translation
- Audio. Noise addition, speed changes
Augmentation increases diversity and improves generalization.
4.4 Data Splitting
Data must be split into:
- Training set. Used to teach the model
- Validation set. Used to tune parameters and prevent overfitting
- Test set. Held back until final evaluation
Splits must be representative and, for time-series data, chronological (train on past, test on future).
Section 5: Stage 4—Model Development
5.1 Algorithm Selection
Choose algorithms based on the problem, data, and constraints:
- Simple problems with structured data. Linear regression, logistic regression, decision trees
- Complex structured data. Random forests, gradient boosting (XGBoost)
- Images. Convolutional neural networks (CNNs)
- Text and sequences. Transformers, RNNs/LSTMs
- When interpretability is critical. Decision trees, linear models
5.2 Training
Training is the process of teaching the model. Key considerations:
- Compute resources. GPUs or TPUs for deep learning
- Training time. Hours to weeks depending on model size and data
- Hyperparameter tuning. Finding the right settings for optimal performance
- Overfitting prevention. Techniques like regularization, dropout, early stopping
5.3 Validation and Testing
Before deployment, models must be validated:
- Performance metrics. Accuracy, precision, recall, F1, AUC, depending on the problem
- Fairness testing. Disparate impact across demographic groups
- Robustness testing. Performance on edge cases, adversarial inputs
- Explainability. Can the model’s decisions be explained?
Validation should be rigorous. A model that passes validation has a much higher chance of succeeding in production.
5.4 Model Selection
Often, multiple models are trained and compared. The final selection balances:
Section 6: Stage 5—Deployment
6.1 Deployment Strategies
Deployment can take several forms:
- Batch inference. Model processes data periodically (e.g., overnight fraud scoring)
- Real-time API. Model serves predictions on demand (e.g., chatbot responses)
- Edge deployment. Model runs on device (e.g., facial recognition on phone)
- Embedded. Model integrated into existing applications
The choice depends on latency requirements, data volume, and infrastructure.
6.2 Integration
Deployment requires integration with existing systems:
- Data pipelines. How does data flow into the model?
- Output handling. How are predictions used? Who or what receives them?
- Fallback logic. What happens when the model fails or is uncertain?
- User interfaces. How do users interact with the model?
6.3 Canary and A/B Testing
To reduce risk, deploy incrementally:
- Canary deployment. Roll out to a small percentage of users, monitor, then expand
- A/B testing. Compare model performance against existing system or baseline
- Shadow mode. Run model in parallel without affecting decisions; validate before full rollout
6.4 Rollback Plan
Always have a rollback plan. If the model performs poorly or causes issues, you must be able to revert quickly.
Section 7: Stage 6—Monitoring and Maintenance
7.1 Why Monitoring Matters
AI systems degrade over time. Monitoring ensures they continue to perform as expected.
Common degradation causes:
- Data drift. The distribution of input data changes over time
- Concept drift. The relationship between inputs and outputs changes
- Model decay. The model’s performance degrades as it ages
- Operational issues. Infrastructure failures, latency increases
7.2 What to Monitor
| Category | What to Monitor | Why |
|---|---|---|
| Model Performance | Accuracy, precision, recall, business metrics | Detecting degradation |
| Data Drift | Input distributions, feature statistics | Identifying changing conditions |
| Concept Drift | Relationship between inputs and outputs | Detecting fundamental shifts |
| Operational Metrics | Latency, throughput, error rates, uptime | Ensuring system reliability |
| Fairness Drift | Disparate impact over time | Preventing emerging bias |
7.3 Retraining Strategies
When performance degrades, models need retraining. Options:
- Scheduled retraining. Retrain at regular intervals (e.g., weekly, monthly)
- Trigger-based retraining. Retrain when drift or performance crosses thresholds
- Continuous learning. Models update incrementally with new data
Retraining must be managed—models that retrain too often can become unstable.
7.4 Model Retirement
Eventually, models become obsolete. Retirement should be planned:
- Decommissioning. Shut down gracefully
- Data retention. Ensure compliance with data retention policies
- Documentation. Record why the model was retired, what replaced it
- Lessons learned. Feed back into future projects
Section 8: How MHTECHIN Helps Across the AI Lifecycle
Navigating the AI lifecycle requires expertise across all stages—from problem definition to ongoing maintenance. MHTECHIN helps organizations build and manage AI systems that succeed.
8.1 For Strategy and Planning
MHTECHIN helps organizations:
- Define the problem. Clarify business objectives, success metrics, feasibility
- Assess data readiness. What data exists? What gaps need filling?
- Plan the lifecycle. Realistic timelines, resource requirements, risk management
8.2 For Data Preparation
MHTECHIN provides hands-on support:
- Data collection. Identify and acquire relevant data sources
- Data cleaning. Remove errors, inconsistencies, duplicates
- Data labeling. Design guidelines, manage labeling, ensure quality
- Data augmentation. Create variations to improve diversity
8.3 For Model Development
MHTECHIN builds and validates models:
- Algorithm selection. Match approach to problem and data
- Training and tuning. Optimize performance
- Validation. Rigorous testing, fairness assessment, explainability
8.4 For Deployment and Monitoring
MHTECHIN manages production AI:
- Deployment pipelines. Integration, scaling, rollback strategies
- Monitoring. Performance tracking, drift detection, alerting
- Retraining. Automated or scheduled retraining workflows
- Governance. Documentation, audit trails, compliance
8.5 The MHTECHIN Approach
MHTECHIN’s AI lifecycle practice is end-to-end. The team understands that success requires discipline at every stage—and that cutting corners leads to failure. For organizations building AI, MHTECHIN provides the expertise to navigate the full journey, from concept to production and beyond.
Section 9: Frequently Asked Questions
9.1 Q: What is the AI lifecycle?
A: The AI lifecycle is the end-to-end process of developing, deploying, and maintaining AI systems. It includes problem definition, data collection, data preparation, model development, deployment, and ongoing monitoring and maintenance.
9.2 Q: Why is the AI lifecycle important?
A: AI systems are not one-time projects. They require ongoing attention—data changes, models degrade, requirements evolve. A structured lifecycle ensures AI systems remain accurate, reliable, and aligned with business goals.
9.3 Q: What is the most time-consuming stage?
A: Data preparation is often the most time-consuming, taking 60–80% of project time. Cleaning data, labeling, and transforming it for training requires significant effort.
9.4 Q: How do you know if AI is the right solution?
A: Start with the business problem. If the problem involves pattern recognition from data, and you have sufficient quality data, AI may be appropriate. If the problem can be solved with simple rules or existing processes, AI may be overkill.
9.5 Q: How much data do I need?
A: It depends. Simple models may need thousands of examples. Deep learning may need hundreds of thousands or millions. Using pre-trained models with fine-tuning requires less. Quality matters more than quantity.
9.6 Q: What is model drift?
A: Model drift occurs when a model’s performance degrades over time. This can happen because the input data changes (data drift) or the relationship between inputs and outputs changes (concept drift). Monitoring is essential to detect drift.
9.7 Q: How do you deploy AI safely?
A: Safe deployment includes canary or A/B testing (roll out gradually), shadow mode (run without affecting decisions), fallback logic (what happens when the model fails), and a clear rollback plan.
9.8 Q: How often should models be retrained?
A: It depends on the application. Some models need retraining daily; others may be fine for months. Retraining can be scheduled (e.g., weekly), trigger-based (when performance drops), or continuous (incremental updates).
9.9 Q: What is the difference between training, validation, and test data?
A: Training data teaches the model. Validation data tunes parameters and prevents overfitting during development. Test data is held back until final evaluation to measure real-world performance. These sets must be separate and not overlap.
9.10 Q: How does MHTECHIN help with the AI lifecycle?
A: MHTECHIN provides end-to-end support across the AI lifecycle—problem definition, data preparation, model development, deployment, and ongoing monitoring. We help organizations build AI systems that succeed.
Section 10: Conclusion—A Journey, Not a Project
Building AI is not a one-time project. It is a journey that spans problem definition, data preparation, model development, deployment, and ongoing maintenance. Organizations that treat AI as a single event—train once, deploy forever—almost always fail.
Success comes from discipline at every stage. Start with a clear problem. Invest in data quality. Validate rigorously. Deploy incrementally. Monitor continuously. And embrace iteration—lessons from production should feed back into development.
For organizations serious about AI, the lifecycle is not a constraint. It is a framework for sustainable success. With the right approach, AI can deliver lasting value—not just at launch, but for years to come.
Ready to navigate the AI lifecycle with confidence? Explore MHTECHIN’s AI development and deployment services at www.mhtechin.com. From strategy through ongoing maintenance, our team helps you build AI that lasts.
This guide is brought to you by MHTECHIN—helping organizations navigate the AI lifecycle, from data collection to deployment and beyond. For personalized guidance on AI strategy or implementation, reach out to the MHTECHIN team today.
Leave a Reply