Introduction
Imagine an AI agent that can analyze thousands of customer support tickets, draft personalized responses, and even initiate refunds—all without human intervention. Now imagine that same agent accidentally approves a $50,000 refund for a fraudulent claim because it misinterpreted a pattern. Without a human in the loop, that mistake becomes a costly reality.
This is why Human-in-the-Loop (HITL) has become one of the most critical design patterns in enterprise agentic AI. As autonomous agents gain more decision-making power, the question isn’t whether they can act—it’s whether they should act without oversight. HITL provides the safety valve that enables organizations to harness AI’s efficiency while maintaining human judgment, accountability, and ethical boundaries .
According to a 2026 survey of enterprise AI leaders, 78% of organizations implementing agentic AI require human approval for high-stakes actions, and 65% have established formal human-in-the-loop protocols as a prerequisite for deployment . The message is clear: autonomy without oversight is not just risky—it’s unacceptable in regulated industries.
In this comprehensive guide, you’ll learn:
- What Human-in-the-Loop means in the context of agentic AI
- The spectrum of HITL patterns—from simple approvals to complex collaboration
- How to design effective human-in-the-loop workflows
- Implementation strategies using frameworks like LangGraph, AutoGen, and CrewAI
- Real-world use cases across finance, healthcare, and customer service
- Best practices for balancing autonomy with oversight
Part 1: What Is Human-in-the-Loop for Agentic AI?
Definition and Core Concept
Human-in-the-Loop (HITL) refers to the integration of human judgment, oversight, and intervention into AI-driven workflows. In agentic AI systems, HITL creates structured points where human operators can review, approve, modify, or reject AI-generated decisions before they are executed .

*Figure 1: Core Human-in-the-Loop workflow showing decision gates and intervention points*
Why HITL Matters in 2026
| Challenge | Without HITL | With HITL |
|---|---|---|
| Hallucinations | AI executes based on false information | Human catches errors before execution |
| Regulatory Compliance | Violations possible | Human verification ensures compliance |
| Ethical Decisions | No ethical reasoning | Human judgment for sensitive cases |
| Accountability | Unclear responsibility | Clear chain of human oversight |
| Trust | Low user confidence | Higher trust through transparency |
The Spectrum of Human Involvement
Human involvement exists on a spectrum—from minimal oversight to deep collaboration :
| Pattern | Human Role | AI Role | Best For |
|---|---|---|---|
| Human-in-the-Loop | Approver/Reviewer | Executor | High-stakes decisions, regulatory compliance |
| Human-on-the-Loop | Monitor | Autonomous | Routine workflows, exception handling |
| Human-in-Command | Decision-maker | Assistant | Strategic decisions, creative work |
| Human-AI Collaboration | Partner | Partner | Complex problem-solving, research |
Part 2: HITL Design Patterns
Pattern 1: Approval Gates
The most common HITL pattern—requiring human approval before high-stakes actions :

| Parameter | Description |
|---|---|
| Threshold | Dollar amount, risk score, confidence threshold |
| Time Limit | Maximum wait time before auto-escalation |
| Fallback | Default action if no response (e.g., hold, escalate) |
Example Use Case: Financial transactions over $10,000 require manager approval before execution.
Pattern 2: Exception Escalation
Agents handle routine tasks but escalate when they encounter ambiguity or uncertainty :
| Scenario | Agent Response |
|---|---|
| Confidence High (>90%) | Auto-execute, log for audit |
| Confidence Medium (70-90%) | Execute with flag for review |
| Confidence Low (<70%) | Pause, escalate to human |
| Ambiguous Intent | Request clarification from human |
Example Use Case: Customer support agent handles standard returns automatically, escalates complex disputes to human agents.
Pattern 3: Progressive Autonomy
Autonomy levels increase as trust is established through performance tracking :
| Stage | Autonomy Level | Oversight |
|---|---|---|
| Stage 1 | 0% (Suggestion only) | Human reviews all actions |
| Stage 2 | 25% (Low-confidence actions require approval) | Human reviews exceptions |
| Stage 3 | 50% (Medium-confidence auto-execute) | Human monitors dashboard |
| Stage 4 | 75% (High-confidence auto-execute) | Human reviews summary |
| Stage 5 | 90% (Full autonomy) | Human sets policies only |
Pattern 4: Interactive Refinement
Humans and agents collaborate iteratively to improve outputs :
python
# Interactive refinement pattern
def refine_with_human(agent_output):
human_feedback = request_feedback(agent_output)
if human_feedback.requires_changes:
refined = agent.revise(human_feedback.suggestions)
return refine_with_human(refined) # Continue loop
return agent_output
Example Use Case: Content generation where human editors review, provide feedback, and agents refine until approval.
Pattern 5: Human-as-Resource
Agents query humans for specific expertise or information when needed :
| Scenario | Agent Action |
|---|---|
| Missing Information | “What is the approval limit for this client?” |
| Expert Judgment | “Does this medical case meet criteria for escalation?” |
| Context Clarification | “Was this customer previously flagged for fraud?” |
Part 3: Implementation Frameworks and Patterns
LangGraph – Human-in-the-Loop with Breakpoints
LangGraph provides built-in support for human-in-the-loop through breakpoints and interrupts . The framework allows you to pause execution at specific nodes, wait for human input, and resume with updated state.
python
from langgraph.graph import StateGraph, END
from langgraph.checkpoint import MemorySaver
class AgentState(TypedDict):
messages: list
requires_approval: bool
approval_status: str
def approval_node(state: AgentState):
"""Human approval checkpoint."""
if state["requires_approval"]:
# Execution pauses here
return {"approval_status": "pending"}
return state
def after_approval(state: AgentState):
"""Continue after human decision."""
if state["approval_status"] == "approved":
return execute_action(state)
else:
return {"messages": ["Action rejected by human"]}
# Build graph with checkpoint
builder = StateGraph(AgentState)
builder.add_node("draft_action", draft_node)
builder.add_node("approve", approval_node)
builder.add_node("execute", after_approval)
builder.add_edge("draft_action", "approve")
builder.add_conditional_edges("approve", should_continue, {"execute": "execute", END: END})
# Add checkpointing for persistence
memory = MemorySaver()
graph = builder.compile(checkpointer=memory)
# Human intervention at approval_node
config = {"configurable": {"thread_id": "user_session_123"}}
result = graph.invoke(input, config)
# Human reviews and provides decision
human_decision = {"approval_status": "approved"}
graph.update_state(config, human_decision, as_node="approve")
AutoGen – Human Proxy Agent
AutoGen’s UserProxyAgent provides built-in human-in-the-loop capabilities :
python
from autogen import AssistantAgent, UserProxyAgent
# Assistant with tool capabilities
assistant = AssistantAgent(
name="assistant",
llm_config=llm_config,
system_message="You are a financial analyst. For any transaction over $10,000, request approval."
)
# Human proxy with code execution and input
user_proxy = UserProxyAgent(
name="human",
human_input_mode="ALWAYS", # Options: NEVER, TERMINATE, ALWAYS
code_execution_config={"work_dir": "coding", "use_docker": False}
)
# Start conversation
user_proxy.initiate_chat(
assistant,
message="Process refund request for customer order #12345 ($15,000)"
)
Human Input Modes:
| Mode | Description |
|---|---|
| NEVER | No human input, fully autonomous |
| TERMINATE | Human input only at termination |
| ALWAYS | Human input before each agent response |
CrewAI – Human Feedback Integration
CrewAI supports human-in-the-loop through task callbacks and human feedback nodes :
python
from crewai import Agent, Task, Crew
def human_review_callback(output):
"""Pause for human review."""
print(f"\n=== HUMAN REVIEW REQUIRED ===")
print(f"Proposed output: {output}")
decision = input("Approve? (y/n/modify): ")
if decision.lower() == 'y':
return {"status": "approved", "output": output}
elif decision.lower() == 'n':
return {"status": "rejected"}
else:
modified = input("Enter modified output: ")
return {"status": "modified", "output": modified}
# Agent with human review
analyst = Agent(
role="Financial Analyst",
goal="Analyze transactions and flag anomalies",
allow_delegation=False
)
review_task = Task(
description="Review flagged transactions and recommend action",
agent=analyst,
callback=human_review_callback,
human_input=True
)
crew = Crew(agents=[analyst], tasks=[review_task])
result = crew.kickoff()
Microsoft Agent Framework – Human Interaction
MAF (formerly AutoGen) provides HumanInteractionAgent for structured human input :
python
from autogen import HumanInteractionAgent, AssistantAgent
human_agent = HumanInteractionAgent(
name="human_reviewer",
description="Human reviewer for high-stakes decisions",
human_input_mode="ALWAYS",
input_parser=lambda x: x.lower() in ["approve", "reject"]
)
approval_agent = AssistantAgent(
name="approval_agent",
system_message="You manage approval workflows. For high-risk actions, request human review."
)
# Team with human oversight
team = GroupChat(
agents=[approval_agent, human_agent],
messages=[],
max_round=5
)
Part 4: Real-World Use Cases
1. Financial Services – Fraud Detection
| Scenario | AI Action | HITL Intervention |
|---|---|---|
| Low-Risk Transaction | Auto-approve | None (logged) |
| Medium-Risk | Flag, hold for 24 hours | Analyst reviews, decides |
| High-Risk | Suspend, immediate escalation | Senior analyst investigation |
| False Positive | Adjust model, human feedback loops | Analyst corrects, agent learns |
Implementation:
- Approval thresholds based on transaction amount and risk score
- Escalation SLA: 2 hours for high-risk
- Feedback loop: Human corrections improve model
2. Healthcare – Clinical Decision Support
| Action | AI Role | HITL Role |
|---|---|---|
| Medication Interaction Check | Flag potential interactions | Pharmacist confirms |
| Diagnosis Suggestion | Provide evidence-based options | Physician makes final decision |
| Prior Authorization | Complete paperwork | Medical director approves |
| Treatment Plan | Generate draft based on guidelines | Doctor reviews, modifies |
Key Requirements:
- Regulatory compliance (HIPAA, FDA)
- Audit trails for all AI-assisted decisions
- Human accountability preserved
3. Customer Service – Escalation Management
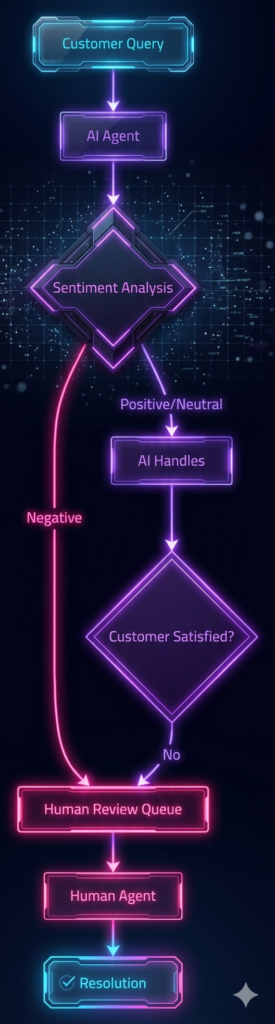
| Scenario | Agent Action | Human Role |
|---|---|---|
| Simple FAQ | Auto-response | Monitor |
| Complex Technical | Research, draft solution | Review, approve |
| Angry Customer | De-escalate, transfer | Handle directly |
| Account Changes | Verify identity, process | Supervisor approval |
4. Content Moderation
| Content Type | AI Action | Human Oversight |
|---|---|---|
| Clear Violation | Auto-remove | Logged, random audit |
| Edge Case | Flag for review | Moderator decides |
| Appealed Decision | Re-evaluate | Senior moderator review |
| Policy Update | Model retraining | Human reviews impact |
5. Software Development – AI-Assisted Coding
| Task | AI Role | Developer Role |
|---|---|---|
| Boilerplate Code | Auto-generate | Review, commit |
| Complex Algorithm | Draft multiple approaches | Select, refine, test |
| Security-Sensitive | Flag vulnerabilities | Security review required |
| Production Deployment | Prepare PR | Senior developer approval |
Part 5: Best Practices for HITL Design
1. Define Clear Trigger Conditions
| Trigger Type | Examples |
|---|---|
| Risk Threshold | Dollar amount, patient safety, legal exposure |
| Confidence Score | <90% confidence requires review |
| Novelty | First-time scenario, new customer type |
| Regulatory | GDPR requests, financial reporting |
2. Optimize Human Review Experience
| Principle | Implementation |
|---|---|
| Context-Rich Interface | Show full conversation history, relevant data |
| Actionable Options | Pre-populated approve/modify/reject buttons |
| Efficiency Tools | Keyboard shortcuts, batch approval |
| Feedback Capture | Structured forms for rejection reasons |
| Performance Metrics | Display reviewer SLA, queue size |
3. Implement Feedback Loops
python
class FeedbackLoop:
def __init__(self):
self.corrections = []
def record_correction(self, original, corrected, reason):
self.corrections.append({
"original": original,
"corrected": corrected,
"reason": reason,
"timestamp": datetime.now()
})
def improve_model(self):
# Retrain or fine-tune based on corrections
# Update confidence thresholds
# Adjust trigger conditions
pass
4. Design for Graceful Failure
| Failure Mode | Mitigation |
|---|---|
| Human Unavailable | Timeout, fallback, secondary reviewer |
| System Timeout | Preserve state, resume after intervention |
| Conflicting Decisions | Tie-breaking rule (senior reviewer, majority) |
| Human Error | Two-person rule for high-risk actions |
5. Maintain Audit Trails
json
{
"audit_id": "audit_12345",
"timestamp": "2026-03-30T10:30:00Z",
"agent_action": {
"type": "refund_request",
"amount": 15000,
"customer": "CUST_789"
},
"human_intervention": {
"reviewer": "jane.doe@company.com",
"decision": "approved",
"timestamp": "2026-03-30T10:35:00Z",
"notes": "Verified customer history, legitimate refund"
},
"outcome": "executed"
}
Part 6: Balancing Autonomy and Oversight
The Autonomy-Oversight Trade-off
| Level | Autonomy | Human Effort | Risk | Speed |
|---|---|---|---|---|
| Full Manual | 0% | High | Lowest | Slow |
| AI-Assisted | 25% | Medium | Low | Medium |
| Conditional Auto | 75% | Low | Medium | Fast |
| Full Auto | 100% | Minimal | Highest | Fastest |
Finding the Right Balance
Factors to Consider:
- Risk Tolerance: Financial services need lower autonomy than internal tools
- Regulatory Environment: Healthcare, finance have stricter requirements
- Maturity: Start with higher oversight, reduce as trust builds
- Cost: Human review has real costs—balance against risk
Progressive Autonomy Implementation
python
class ProgressiveAutonomy:
def __init__(self, initial_level=1):
self.autonomy_level = initial_level
self.performance_metrics = []
def update_autonomy(self, performance):
self.performance_metrics.append(performance)
# Calculate rolling accuracy
recent_performance = self.performance_metrics[-100:]
accuracy = sum(p["correct"] for p in recent_performance) / len(recent_performance)
if accuracy > 0.95 and len(self.performance_metrics) > 1000:
self.autonomy_level = min(self.autonomy_level + 1, 5)
elif accuracy < 0.85:
self.autonomy_level = max(self.autonomy_level - 1, 1)
def should_intervene(self, action):
if self.autonomy_level == 1:
return True # Human reviews all
elif self.autonomy_level == 2:
return action.confidence < 0.7 # Low confidence only
elif self.autonomy_level == 3:
return action.risk_score > 0.5 # High risk only
elif self.autonomy_level >= 4:
return action.risk_score > 0.8 # Very high risk only
return False
Part 7: Security and Governance
Access Control
| Layer | Control |
|---|---|
| Authentication | MFA for human reviewers |
| Authorization | Role-based approval limits (e.g., $10k for managers, $50k for directors) |
| Segregation of Duties | Same person cannot request and approve |
| Session Management | Timeout, re-authentication for sensitive actions |
Audit Requirements
| Requirement | Implementation |
|---|---|
| Immutability | Blockchain or append-only logs |
| Non-repudiation | Digital signatures for approvals |
| Retention | 7+ years for regulated industries |
| Searchability | Indexed logs with filtering |
Compliance Considerations
| Regulation | HITL Requirement |
|---|---|
| GDPR | Right to human review for automated decisions |
| EU AI Act | High-risk systems require human oversight |
| HIPAA | Clinical decisions require licensed professional review |
| SOX | Financial controls require segregation of duties |
Part 8: MHTECHIN’s Expertise in Human-in-the-Loop Systems
At MHTECHIN, we specialize in building responsible agentic AI systems with robust human-in-the-loop capabilities. Our expertise spans:
- Custom HITL Workflows: Designing approval gates, escalation paths, and feedback loops tailored to your business
- Framework Integration: LangGraph, AutoGen, CrewAI, and custom HITL implementations
- Governance & Compliance: Audit trails, access controls, and regulatory compliance
- Progressive Autonomy: Systems that learn from human feedback and increase autonomy safely
MHTECHIN’s solutions ensure that your AI agents are not just powerful—they’re responsible. Contact us to learn how we can help you deploy AI with the right balance of autonomy and oversight.
Conclusion
Human-in-the-Loop is not a limitation on AI—it’s an enabler. By incorporating human judgment at critical decision points, organizations can deploy agentic AI with confidence, knowing that:
- Risks are contained through structured oversight
- Regulatory requirements are satisfied with audit trails
- Trust is built through transparency and accountability
- Performance improves through human feedback loops
The most successful agentic AI deployments in 2026 are not those with the highest autonomy—they’re those with the most thoughtful integration of human judgment. As one enterprise AI leader noted, “We don’t want AI that replaces people. We want AI that makes people better at their jobs—and gives them the final say when it matters most.”
Frequently Asked Questions (FAQ)
Q1: What is Human-in-the-Loop (HITL) in AI?
Human-in-the-Loop is an approach where human judgment is integrated into AI-driven workflows, allowing humans to review, approve, or modify AI-generated decisions before they are executed .
Q2: Why is HITL important for agentic AI?
HITL provides safety, accountability, and regulatory compliance. It prevents AI hallucinations from causing real-world harm, maintains clear accountability chains, and satisfies regulatory requirements for human oversight .
Q3: What are the main HITL patterns?
Key patterns include Approval Gates (human must approve), Exception Escalation (human handles edge cases), Progressive Autonomy (autonomy grows with trust), Interactive Refinement (humans provide feedback), and Human-as-Resource (agents query humans for expertise) .
Q4: How do I implement HITL with LangGraph?
LangGraph supports HITL through breakpoints and checkpoints. You can pause execution at specific nodes, wait for human input, and resume with updated state using interrupt() and update_state() .
Q5: What’s the difference between human-in-the-loop and human-on-the-loop?
Human-in-the-loop requires human approval before action; human-on-the-loop involves monitoring autonomous systems with ability to intervene if needed .
Q6: How do I decide what requires human review?
Consider risk thresholds (dollar amounts, safety impact), confidence scores (low confidence requires review), novelty (new scenarios), and regulatory requirements .
Q7: What frameworks support HITL?
LangGraph, AutoGen (via UserProxyAgent), CrewAI (via callbacks), and Microsoft Agent Framework all provide built-in HITL capabilities .
Q8: How do I balance autonomy with oversight?
Use progressive autonomy—start with high oversight, track performance metrics, and increase autonomy as confidence and accuracy improve .
Leave a Reply