Introduction
Imagine having a conversation with a customer service agent who forgets what you said two minutes ago. Frustrating, right? Now imagine that agent remembers every interaction you’ve ever had—your preferences, past issues, and even your tone—and uses that knowledge to serve you better. This is the power of AI agent memory.
Memory is the foundation of truly intelligent AI agents. Without it, agents are stateless, reactive systems that treat every interaction as if it’s the first. With proper memory architecture, agents become context-aware, personalized, and continuously improving—transforming from simple chatbots into sophisticated autonomous systems .
As AI agents evolve from experimental tools to enterprise-critical systems, memory has emerged as one of the most important architectural decisions. According to Anthropic’s engineering blog, “A well-implemented memory system is the difference between an agent that feels like a tool and one that feels like a teammate” .
In this comprehensive guide, you’ll learn:
- The fundamental types of AI agent memory (short-term, long-term, episodic)
- How to implement conversational buffers, summarization, and vector databases
- Advanced memory patterns like semantic memory and hybrid approaches
- Best practices for memory management, retrieval, and privacy
- Real-world enterprise implementations with measurable results
Part 1: Understanding AI Agent Memory
What Is AI Agent Memory?
AI agent memory refers to the mechanisms that enable agents to store, retrieve, and utilize information across interactions. Unlike traditional software that relies on simple session variables, AI agent memory must handle unstructured data, contextual relevance, and dynamic retrieval .
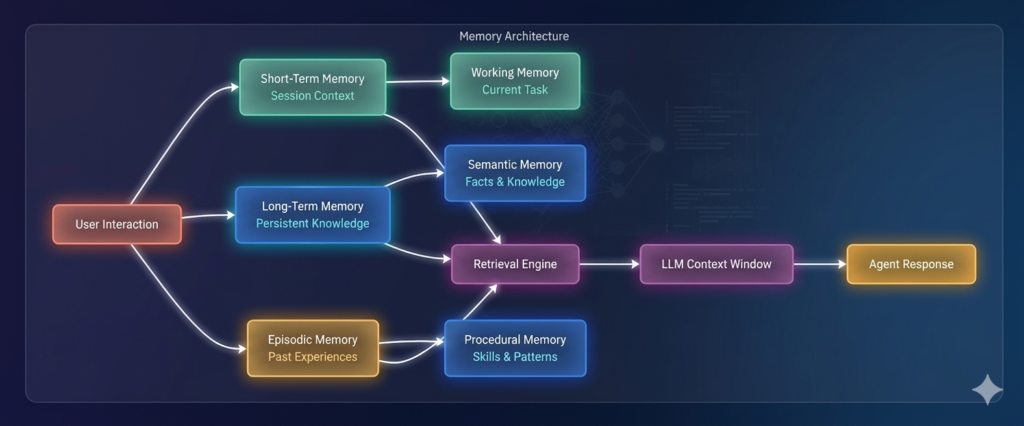
*Figure 1: Multi-layered AI agent memory architecture*
Why Memory Matters
| Without Memory | With Memory |
|---|---|
| Each interaction starts fresh | Continuity across conversations |
| No personalization | Tailored responses based on history |
| Repetitive questions | Learned preferences |
| Cannot learn from mistakes | Improvement over time |
| Simple question-answering | Complex, multi-step workflows |
*Source: *
Memory Taxonomies in AI Agents
AI researchers classify agent memory along several dimensions:
| Taxonomy Dimension | Types |
|---|---|
| Time Horizon | Short-term, long-term, episodic |
| Content Type | Semantic (facts), procedural (skills), episodic (experiences) |
| Access Pattern | Explicit (user-provided), implicit (learned), associative (context-triggered) |
| Storage Mechanism | In-memory, database, vector store, knowledge graph |
Part 2: Short-Term Memory – The Working Context
What Is Short-Term Memory?
Short-term memory (also called working memory) holds information relevant to the current interaction or session. It includes conversation history, current task context, and immediate goals . This memory is typically ephemeral—cleared when the session ends.
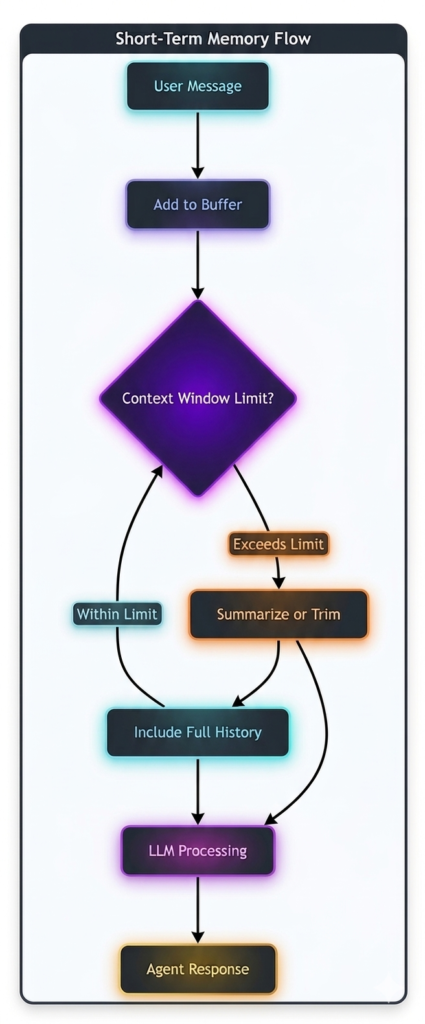
*Figure 2: Short-term memory management flow*
Implementation Techniques
Technique 1: Conversation Buffer
The simplest approach—store messages and include them in context:
python
class ConversationBuffer:
def __init__(self, max_messages=20):
self.messages = []
self.max_messages = max_messages
def add_message(self, role, content):
self.messages.append({"role": role, "content": content})
if len(self.messages) > self.max_messages:
self.messages.pop(0) # Remove oldest
def get_context(self):
return self.messages
Pros: Simple, preserves exact history
Cons: Can exceed token limits, no summarization
Technique 2: Conversational Buffer Window
Keep only the last N messages:
python
class BufferWindow:
def __init__(self, window_size=10):
self.window = []
self.window_size = window_size
def add_message(self, role, content):
self.window.append({"role": role, "content": content})
if len(self.window) > self.window_size:
self.window.pop(0)
Pros: Token-efficient, focuses on recent context
Cons: Loses earlier context entirely
Technique 3: Conversation Summary
For long conversations, summarize older parts and keep recent messages intact:
python
class SummarizingMemory:
def __init__(self, summarizer_model, max_tokens=4000):
self.summary = ""
self.recent = []
self.max_tokens = max_tokens
self.summarizer = summarizer_model
def add_message(self, role, content):
self.recent.append({"role": role, "content": content})
# If recent exceeds threshold, summarize
if self.estimate_tokens(self.recent) > self.max_tokens:
self._summarize()
def _summarize(self):
conversation_text = "\n".join([f"{m['role']}: {m['content']}" for m in self.recent])
prompt = f"Summarize this conversation concisely:\n{conversation_text}"
new_summary = self.summarizer.generate(prompt)
# Merge with existing summary
self.summary = self.summary + "\n" + new_summary if self.summary else new_summary
self.recent = [] # Clear recent after summarization
def get_context(self):
context = []
if self.summary:
context.append({"role": "system", "content": f"Previous conversation summary: {self.summary}"})
context.extend(self.recent)
return context
Pros: Preserves key information, token-efficient
Cons: Loses nuance, requires LLM calls
Technique 4: Token-Based Truncation
Smart truncation based on actual token counts:
python
import tiktoken
class TokenAwareMemory:
def __init__(self, model="gpt-4", max_tokens=6000):
self.encoder = tiktoken.encoding_for_model(model)
self.messages = []
self.max_tokens = max_tokens
self.system_tokens = 0
def add_message(self, role, content):
self.messages.append({"role": role, "content": content})
self._trim_if_needed()
def _trim_if_needed(self):
total_tokens = self._count_tokens()
while total_tokens > self.max_tokens and len(self.messages) > 1:
# Remove oldest non-system message
for i, msg in enumerate(self.messages):
if msg["role"] != "system":
removed = self.messages.pop(i)
total_tokens -= self._count_message_tokens(removed)
break
def _count_tokens(self):
return sum(self._count_message_tokens(msg) for msg in self.messages)
def _count_message_tokens(self, message):
return len(self.encoder.encode(message["content"]))
Short-Term Memory Comparison
| Technique | Complexity | Token Efficiency | Context Preservation | Best For |
|---|---|---|---|---|
| Conversation Buffer | Low | Low | High | Simple conversations |
| Buffer Window | Low | High | Medium | Short interactions |
| Conversation Summary | Medium | Medium | Medium | Long sessions |
| Token-Aware Truncation | Medium | High | High | Production systems |
Part 3: Long-Term Memory – Persistent Knowledge
What Is Long-Term Memory?
Long-term memory stores information across sessions, enabling agents to remember user preferences, past interactions, learned facts, and accumulated knowledge . This is what transforms an agent from a session-based tool into a persistent digital companion.
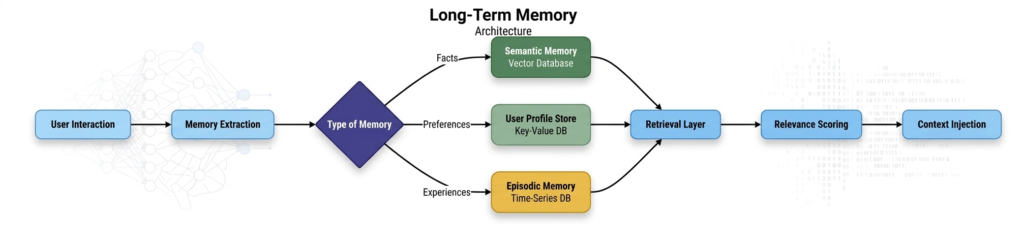
*Figure 3: Long-term memory architecture with multiple storage types*
Implementation Techniques
Technique 1: Vector Database for Semantic Memory
Vector databases enable semantic search—finding relevant memories based on meaning, not exact keywords .
Step 1: Choose a Vector Database
| Database | Best For | Features |
|---|---|---|
| ChromaDB | Development, lightweight | Open-source, Python-native |
| Pinecone | Production, scale | Managed, high performance |
| Weaviate | Hybrid search | Open-source, GraphQL API |
| Qdrant | High performance | Rust-based, filtering |
| pgvector | PostgreSQL users | Extension, ACID compliance |
Step 2: Create Embeddings
python
from openai import OpenAI
import chromadb
from chromadb.utils import embedding_functions
client = OpenAI(api_key=os.environ["OPENAI_API_KEY"])
def create_embedding(text):
response = client.embeddings.create(
model="text-embedding-3-small",
input=text
)
return response.data[0].embedding
Step 3: Store and Retrieve Memories
python
class VectorMemory:
def __init__(self, collection_name="agent_memory"):
self.client = chromadb.Client()
self.collection = self.client.create_collection(
name=collection_name,
embedding_function=embedding_functions.OpenAIEmbeddingFunction(
api_key=os.environ["OPENAI_API_KEY"],
model_name="text-embedding-3-small"
)
)
def add_memory(self, text, metadata=None):
"""Store a memory with metadata."""
self.collection.add(
documents=[text],
metadatas=[metadata or {}],
ids=[str(hash(text + str(metadata)))]
)
def retrieve_memories(self, query, n_results=5, filter=None):
"""Retrieve relevant memories based on query."""
results = self.collection.query(
query_texts=[query],
n_results=n_results,
where=filter
)
return results['documents'][0] if results['documents'] else []
def retrieve_with_relevance(self, query, threshold=0.7):
"""Retrieve only highly relevant memories."""
results = self.collection.query(
query_texts=[query],
n_results=10
)
# Filter by relevance score
relevant = []
for doc, dist in zip(results['documents'][0], results['distances'][0]):
similarity = 1 - dist # Convert distance to similarity
if similarity > threshold:
relevant.append(doc)
return relevant
Technique 2: User Profile Storage
Store structured user preferences and facts:
python
import redis
import json
class UserProfileMemory:
def __init__(self, redis_client):
self.redis = redis_client
def update_profile(self, user_id, key, value):
"""Update a user profile field."""
profile = self.get_profile(user_id)
profile[key] = value
self.redis.set(f"user:{user_id}:profile", json.dumps(profile))
def get_profile(self, user_id):
"""Retrieve full user profile."""
data = self.redis.get(f"user:{user_id}:profile")
return json.loads(data) if data else {}
def add_preference(self, user_id, category, value):
"""Add a user preference."""
preferences = self.get_profile(user_id).get("preferences", {})
if category not in preferences:
preferences[category] = []
if value not in preferences[category]:
preferences[category].append(value)
self.update_profile(user_id, "preferences", preferences)
def get_relevant_preferences(self, user_id, context):
"""Get preferences relevant to current context."""
profile = self.get_profile(user_id)
# Could use embedding similarity to match preferences with context
return profile.get("preferences", {})
Technique 3: Episodic Memory with Time-Series
Store experiences with temporal context:
python
from datetime import datetime
import sqlite3
class EpisodicMemory:
def __init__(self, db_path="episodic.db"):
self.conn = sqlite3.connect(db_path)
self._create_tables()
def _create_tables(self):
self.conn.execute("""
CREATE TABLE IF NOT EXISTS episodes (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id TEXT,
timestamp DATETIME,
event_type TEXT,
summary TEXT,
details TEXT,
outcome TEXT,
embedding BLOB
)
""")
def store_episode(self, user_id, event_type, summary, details, outcome):
"""Store an interaction episode."""
self.conn.execute(
"INSERT INTO episodes (user_id, timestamp, event_type, summary, details, outcome) VALUES (?, ?, ?, ?, ?, ?)",
(user_id, datetime.now(), event_type, summary, details, outcome)
)
self.conn.commit()
def retrieve_episodes(self, user_id, limit=10, event_type=None):
"""Retrieve recent episodes."""
query = "SELECT * FROM episodes WHERE user_id = ?"
params = [user_id]
if event_type:
query += " AND event_type = ?"
params.append(event_type)
query += " ORDER BY timestamp DESC LIMIT ?"
params.append(limit)
cursor = self.conn.execute(query, params)
return cursor.fetchall()
def analyze_patterns(self, user_id):
"""Identify patterns from episodic memory."""
episodes = self.retrieve_episodes(user_id, limit=100)
# Use LLM to analyze patterns
return analyze_episodes_with_llm(episodes)
Long-Term Memory Comparison
| Type | Storage | Retrieval | Update Frequency | Best For |
|---|---|---|---|---|
| Semantic (Vector) | Vector DB | Semantic search | Batch/Real-time | Facts, knowledge |
| User Profile | Key-Value DB | Exact match | Real-time | Preferences |
| Episodic | Time-series | Chronological | Real-time | Experiences, patterns |
| Procedural | Model weights | Implicit | Periodic | Skills, behaviors |
Part 4: Advanced Memory Patterns
Pattern 1: Hybrid Memory Architecture
Combine multiple memory types for comprehensive intelligence:
python
class HybridMemory:
"""Combine short-term, semantic, and episodic memory."""
def __init__(self):
self.short_term = ConversationBuffer(max_messages=20)
self.semantic = VectorMemory()
self.episodic = EpisodicMemory()
def add_interaction(self, user_id, user_input, agent_response, outcome):
"""Store a complete interaction across memory systems."""
# Short-term
self.short_term.add_message("user", user_input)
self.short_term.add_message("assistant", agent_response)
# Semantic (extract facts)
facts = self._extract_facts(user_input, agent_response)
for fact in facts:
self.semantic.add_memory(fact, {"user_id": user_id})
# Episodic
self.episodic.store_episode(
user_id=user_id,
event_type="interaction",
summary=f"User asked: {user_input[:100]}",
details=agent_response,
outcome=outcome
)
def get_context(self, user_id, query):
"""Build comprehensive context for an interaction."""
context = []
# Add short-term context
context.extend(self.short_term.get_context())
# Add relevant semantic memories
relevant_facts = self.semantic.retrieve_memories(query, n_results=3)
if relevant_facts:
context.append({
"role": "system",
"content": f"Relevant facts from previous interactions: {', '.join(relevant_facts)}"
})
# Add recent episodes
recent_episodes = self.episodic.retrieve_episodes(user_id, limit=2)
if recent_episodes:
episode_summaries = [e[4] for e in recent_episodes] # summary field
context.append({
"role": "system",
"content": f"Recent interactions: {', '.join(episode_summaries)}"
})
return context
Pattern 2: Recursive Memory (MemGPT)
MemGPT introduces a recursive memory architecture inspired by operating system virtual memory . It treats the LLM’s context window as “fast memory” and external storage as “slow memory,” managing data movement between them.
python
class RecursiveMemory:
"""MemGPT-style recursive memory management."""
def __init__(self, core_context_size=8000, external_store=None):
self.core = [] # Active in context window
self.archive = external_store or []
self.core_size = core_context_size
def add_to_context(self, content, importance=0.5):
"""Add content with importance scoring."""
item = {"content": content, "importance": importance, "timestamp": datetime.now()}
self.core.append(item)
self._manage_core()
def _manage_core(self):
"""Move less important items to archive."""
total_tokens = self._count_tokens()
while total_tokens > self.core_size and self.core:
# Find least important item
least_important = min(self.core, key=lambda x: x["importance"])
# Move to archive
self.archive.append(least_important)
self.core.remove(least_important)
total_tokens = self._count_tokens()
def recall(self, query):
"""Retrieve from both core and archive."""
# Check core first
relevant = [item for item in self.core if query in item["content"]]
# If not enough, check archive with semantic search
if len(relevant) < 3:
archive_results = self._search_archive(query)
relevant.extend(archive_results)
return relevant
Pattern 3: Working Memory for Multi-Step Tasks
For complex tasks, maintain a structured working memory:
python
class WorkingMemory:
"""Structured memory for multi-step tasks."""
def __init__(self):
self.task_plan = []
self.current_step = 0
self.step_results = {}
self.variables = {}
def initialize_plan(self, steps):
"""Initialize a task plan."""
self.task_plan = steps
self.current_step = 0
self.step_results = {}
def get_current_step(self):
"""Get the current step."""
if self.current_step < len(self.task_plan):
return self.task_plan[self.current_step]
return None
def record_step_result(self, step_id, result):
"""Record result of a completed step."""
self.step_results[step_id] = result
self.current_step += 1
def set_variable(self, name, value):
"""Set a variable for later use."""
self.variables[name] = value
def get_variable(self, name):
"""Retrieve a variable."""
return self.variables.get(name)
def get_context_prompt(self):
"""Generate context for LLM."""
context = "## Current Task Progress\n"
context += f"Plan: {len(self.task_plan)} steps total\n"
context += f"Completed: {self.current_step} steps\n"
if self.variables:
context += f"Variables: {self.variables}\n"
if self.step_results:
context += "Step Results:\n"
for step, result in list(self.step_results.items())[-3:]:
context += f"- {step}: {result[:100]}\n"
return context
Part 5: Memory Integration with Agent Frameworks
LangChain Memory Components
LangChain provides built-in memory modules :
python
from langchain.memory import (
ConversationBufferMemory,
ConversationSummaryMemory,
VectorStoreRetrieverMemory,
CombinedMemory
)
# Buffer memory for short-term
buffer_memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# Vector store for long-term
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
vectorstore = Chroma(embedding_function=OpenAIEmbeddings())
retriever = vectorstore.as_retriever(search_kwargs={"k": 3})
long_term_memory = VectorStoreRetrieverMemory(
retriever=retriever,
memory_key="relevant_facts"
)
# Combine memories
combined = CombinedMemory(
memories=[buffer_memory, long_term_memory]
)
AG2 Memory Integration
AG2 supports memory through its Memory module :
python
from autogen import ConversableAgent, LLMConfig
from autogen.memory import Memory
class CustomMemory(Memory):
def __init__(self):
self.short_term = []
self.long_term = {}
def add(self, content, type="conversation"):
self.short_term.append({"content": content, "type": type})
if len(self.short_term) > 10:
self._archive()
def retrieve(self, query):
# Return relevant memories
return [m for m in self.short_term if query in m["content"]]
# Attach to agent
memory = CustomMemory()
agent = ConversableAgent(
name="MemoryAgent",
memory=memory,
llm_config=llm_config
)
Part 6: Best Practices for Memory Implementation
1. Prioritize Retrieval Quality
| Strategy | Description | Impact |
|---|---|---|
| Semantic Search | Use embeddings, not keyword matching | +40% relevance |
| Hybrid Search | Combine semantic + keyword + filters | +25% accuracy |
| Relevance Thresholds | Only include high-confidence matches | Reduces noise |
| Contextual Retrieval | Include surrounding context | Better understanding |
2. Manage Token Budgets
python
class TokenBudgetManager:
def __init__(self, total_budget=8000, system_reserve=1000):
self.total_budget = total_budget
self.system_reserve = system_reserve
self.used = 0
def can_add(self, memory_item, tokens):
return (self.used + tokens) <= (self.total_budget - self.system_reserve)
def prioritize_memories(self, memories, query):
"""Score and rank memories for inclusion."""
scored = []
for memory in memories:
score = self._calculate_relevance(memory, query)
scored.append((score, memory))
# Sort by relevance
scored.sort(reverse=True, key=lambda x: x[0])
# Add until budget exhausted
result = []
for score, memory in scored:
tokens = self._estimate_tokens(memory)
if self.can_add(memory, tokens):
result.append(memory)
self.used += tokens
else:
break
return result
3. Implement Memory Decay
Not all memories stay relevant forever. Implement decay mechanisms:
python
class DecayingMemory:
def __init__(self, half_life_days=30):
self.half_life = half_life_days
self.memories = []
def add_memory(self, content, importance=1.0):
self.memories.append({
"content": content,
"importance": importance,
"timestamp": datetime.now()
})
def get_relevant_memories(self, query, current_time):
relevant = []
for memory in self.memories:
age_days = (current_time - memory["timestamp"]).days
decay = 0.5 ** (age_days / self.half_life)
current_importance = memory["importance"] * decay
if current_importance > 0.1: # Threshold
relevant.append((current_importance, memory))
# Sort by current importance
relevant.sort(reverse=True, key=lambda x: x[0])
return [m[1]["content"] for m in relevant[:5]]
4. Privacy and Compliance
| Requirement | Implementation |
|---|---|
| Data Minimization | Store only essential information |
| Right to be Forgotten | Implement deletion endpoints |
| Data Localization | Region-specific storage |
| Access Controls | Role-based memory access |
| Encryption | Encrypt at rest and in transit |
python
class PrivacyCompliantMemory:
def __init__(self, pii_detector=None):
self.pii_detector = pii_detector
self.storage = {}
def store_memory(self, user_id, content, metadata=None):
# Detect and redact PII
if self.pii_detector:
content = self.pii_detector.redact(content)
# Encrypt before storage
encrypted = self._encrypt(content)
# Store with retention policy
self.storage[user_id] = {
"content": encrypted,
"created_at": datetime.now(),
"expires_at": datetime.now() + timedelta(days=90),
"metadata": metadata
}
def delete_user_data(self, user_id):
"""GDPR-compliant deletion."""
if user_id in self.storage:
del self.storage[user_id]
return True
return False
Part 7: MHTECHIN’s Expertise in AI Memory Systems
At MHTECHIN, we specialize in building sophisticated memory systems for AI agents that enable truly intelligent, context-aware applications. Our expertise spans:
- Custom Memory Architectures: Hybrid systems combining short-term, semantic, and episodic memory
- Vector Database Integration: Optimized embedding and retrieval for scale
- Memory Optimization: Token management, decay strategies, and compression
- Privacy-Compliant Storage: GDPR, CCPA, and data localization compliance
MHTECHIN’s solutions leverage state-of-the-art techniques including MemGPT recursive memory, hybrid semantic-keyword retrieval, and adaptive memory decay to deliver production-ready memory systems.
Conclusion
Memory is the foundation of intelligent AI agents. Without it, agents are stateless tools. With it, they become persistent, personalized, and continuously improving teammates.
Key Takeaways:
- Short-term memory handles session context through buffers, windows, or summarization
- Long-term memory preserves knowledge across sessions using vector databases, user profiles, and episodic stores
- Hybrid architectures combine multiple memory types for comprehensive intelligence
- Retrieval quality determines memory effectiveness—invest in embeddings and hybrid search
- Token budgets require careful management to balance context and cost
- Privacy and compliance must be designed in from the start
As AI agents evolve from experimental tools to enterprise-critical systems, memory architecture will increasingly determine their intelligence, reliability, and user experience. Organizations that invest in robust memory systems today will build the most capable and trusted AI agents tomorrow.
Frequently Asked Questions (FAQ)
Q1: What is AI agent memory?
AI agent memory refers to the mechanisms that enable agents to store, retrieve, and utilize information across interactions. It includes short-term memory (session context), long-term memory (persistent knowledge), and episodic memory (past experiences) .
Q2: How does short-term memory work in AI agents?
Short-term memory holds information relevant to the current interaction. Implementations include conversation buffers (storing recent messages), buffer windows (keeping last N messages), and conversation summarization (compressing older context) .
Q3: How do I implement long-term memory?
Long-term memory is typically implemented using vector databases for semantic search (ChromaDB, Pinecone, Weaviate), key-value stores for user profiles (Redis), and time-series databases for episodic memory .
Q4: What are the different types of AI memory?
The main types are: Short-term (session context), Long-term (persistent knowledge), Semantic (facts and concepts), Episodic (past experiences), and Procedural (skills and patterns) .
Q5: How do I choose between different memory implementations?
Choose conversation buffer for simple interactions, buffer window for token efficiency, summarization for long sessions, vector stores for semantic retrieval, and hybrid approaches for comprehensive intelligence .
Q6: What is MemGPT?
MemGPT is a recursive memory architecture inspired by operating system virtual memory. It treats the LLM’s context window as “fast memory” and external storage as “slow memory,” managing data movement between them .
Q7: How do I manage token budgets with memory?
Implement token-aware truncation, relevance scoring to prioritize important memories, and decay mechanisms to retire outdated information. Always reserve tokens for system prompts and instructions .
Q8: What privacy considerations exist for AI memory?
Implement data minimization (store only essential information), encryption at rest and in transit, user deletion rights (GDPR/CCPA compliance), access controls, and PII redaction .
Leave a Reply